In preparation for some upcoming work with the End of Term 2016 crawl and a few conference talks I should be prepared for, I thought it might be a good thing to start doing a bit of long-overdue analysis of the End of Term 2012 (EOT2012) dataset.
A little bit of background for those that aren’t familiar with the End of Term program. Back in 2008 a group of institutions got together to collaboratively collect a snapshot of the federal government with a hope to preserve the transition from the Bush administration into what became the Obama administration. In 2012 this group added a few additional partners and set out to take another snapshot of the federal Web presence.
The EOT2008 dataset was studied as part of a research project funded by IMLS but the EOT2012 really hasn’t been looked at too much since it was collected.
As part of the EOT process, there are several institutions that crawl data that is directly relevant to their collection missions and then we all share what we collect with the group as a whole for any of the institutions who are interested in acquiring a set of the entire collected EOT archive. In 2012 the Internet Archive, Library of Congress and the UNT Libraries were the institutions that committed resources to crawling. UNT also was interested in acquiring this archive for its collection which is why I have a copy locally.
For the analysis that I am interested in doing for this blog post, I took a copy of the combined CDX files for each of the crawling institutions as the basis of my dataset. There was one combined CDX for each of IA, LOC, and UNT.
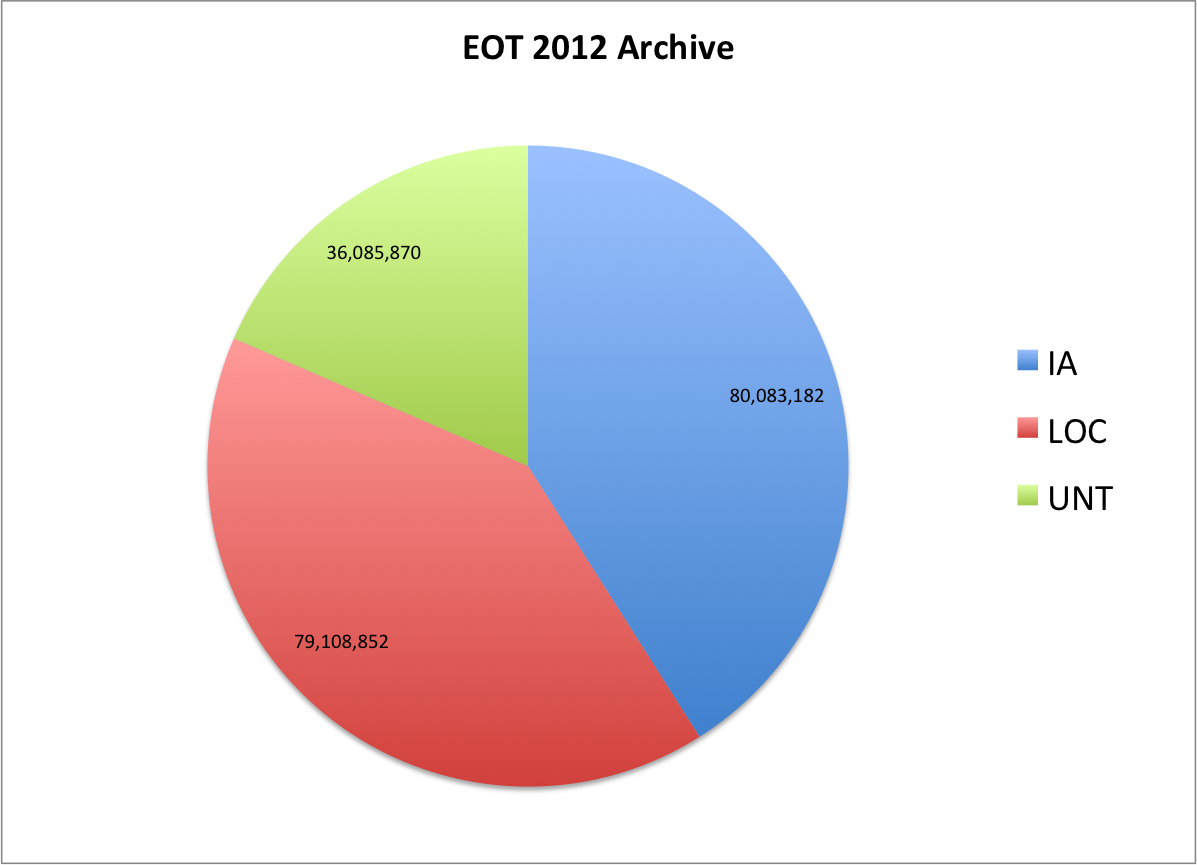
If you look at the three CDX files to see how many total lines are present, this can give you the number of URLs in the collection pretty easily. This ends up being the following
| Collecting Org | Total CDX Entries | % of EOT2012 Archive |
| IA | 80,083,182 | 41.0% |
| LOC | 79,108,852 | 40.5% |
| UNT | 36,085,870 | 18.5% |
| Total | 195,277,904 | 100% |
Here is how that looks as a pie chart.
EOT2016 Collection Distribution
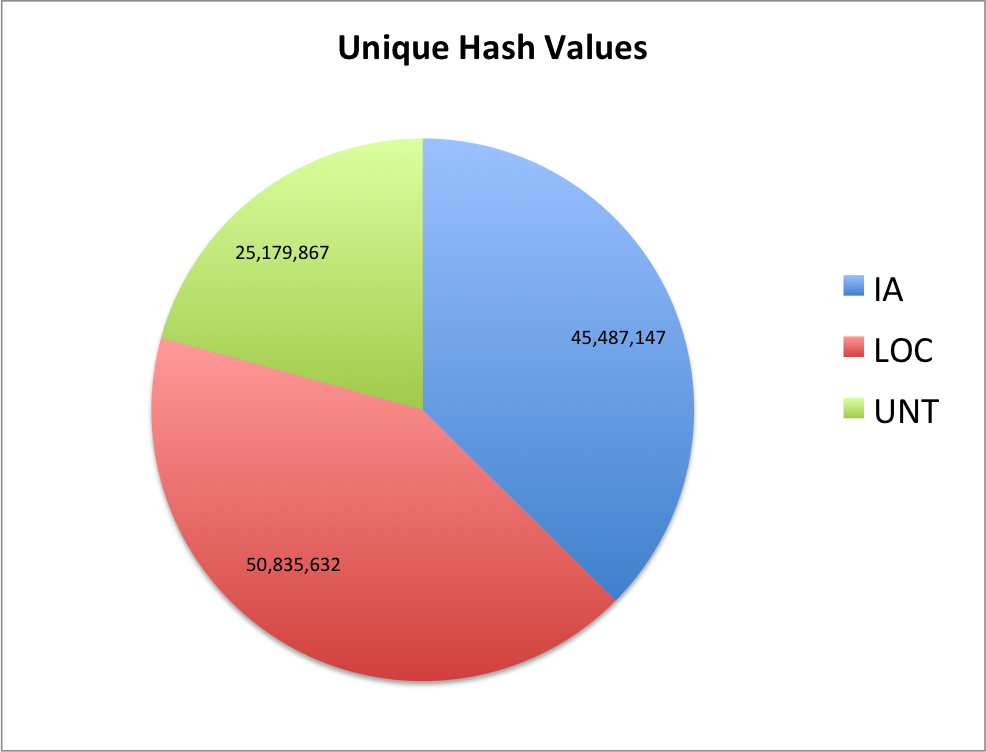
If you pull out all of the content hash values you get the number of “unique files by content hash” in the CDX file. By doing this you are ignoring repeat captures of the same content on different dates, as well the same content occurring at different URL locations on the same or on different hosts.
| Collecting Org | Unique CDX Hashes | % of EOT2012 Archive |
| IA | 45,487,147 | 38.70% |
| LOC | 50,835,632 | 43.20% |
| UNT | 25,179,867 | 21.40% |
| Total | 117,616,637 | 100.00% |
Again as a pie chart
Unique hash values
It looks like there was a little bit of change in the percentages of unique content with UNT and LOC going up a few percentage points and IA going down. I would guess that this is to do with the fact that for the EOT projects, the IA conducted many broad crawls at multiple times during the project that resulted in more overlap.
Here is a table that can give you a sense of how much duplication (based on just the hash values) there is in each of the collections and then overall.
| Collecting Org | Total CDX Entries | Unique CDX Hashes | Duplication |
| IA | 80,083,182 | 45,487,147 | 43.20% |
| LOC | 79,108,852 | 50,835,632 | 35.70% |
| UNT | 36,085,870 | 25,179,867 | 30.20% |
| Total | 195,277,904 | 117,616,637 | 39.80% |
You will see that UNT has the least duplication (possibly more focused crawls with less repeating) than IA (broader with more crawls of the same data?)
Questions to answer.
There were three questions that I wanted to answer for this look at the EOT data.
- How many hashes are common across all CDX files
- How many hashes are unique to only one CDX file
- How many hashes are shared by two CDX files but not by the third.
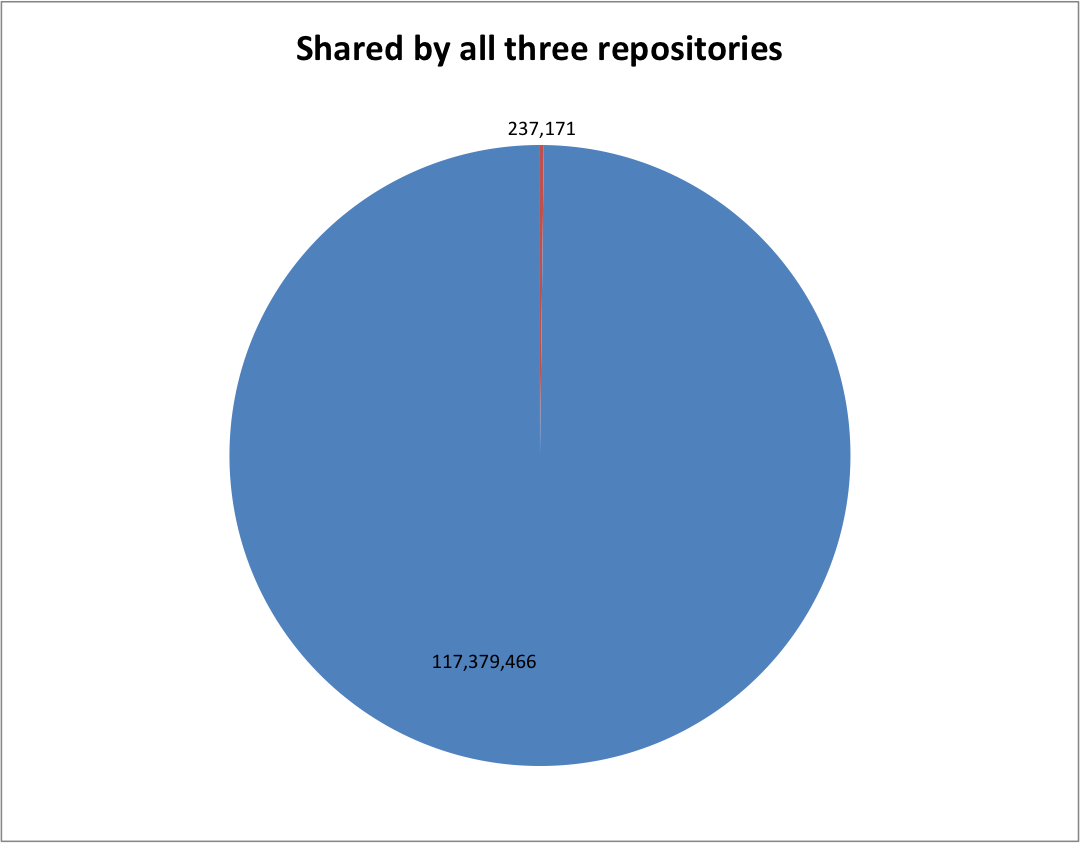
Common Across all CDX files
The first was pretty easy to answer and just required taking all three lists of hashes, and identifying which hash appears in each list (intersection).
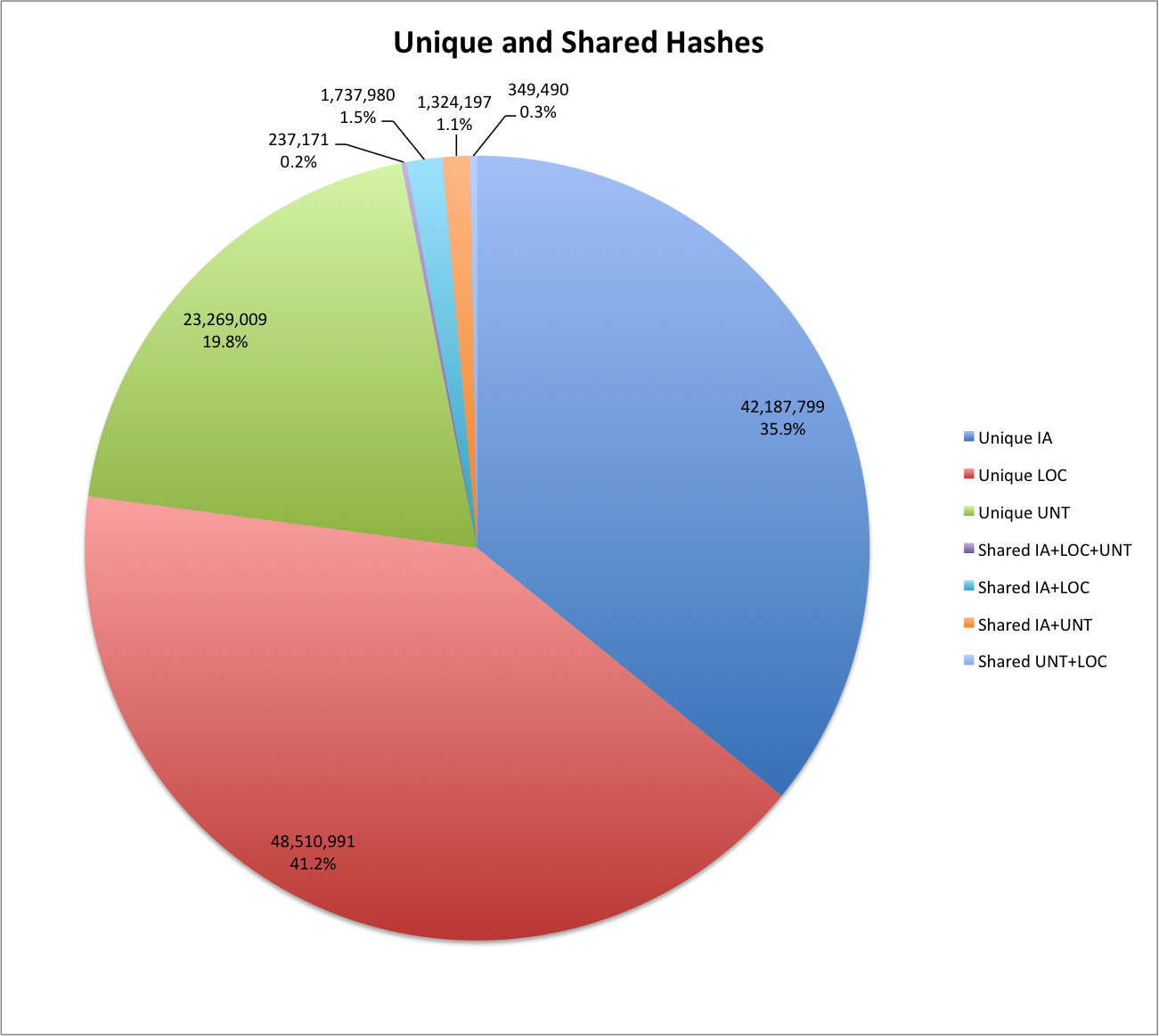
There are only 237,171 (0.2%) hashes shared by IA, LOC and UNT.
Content crawled by all three
You can see that there is a very small amount of content that is present in all three of the CDX files.
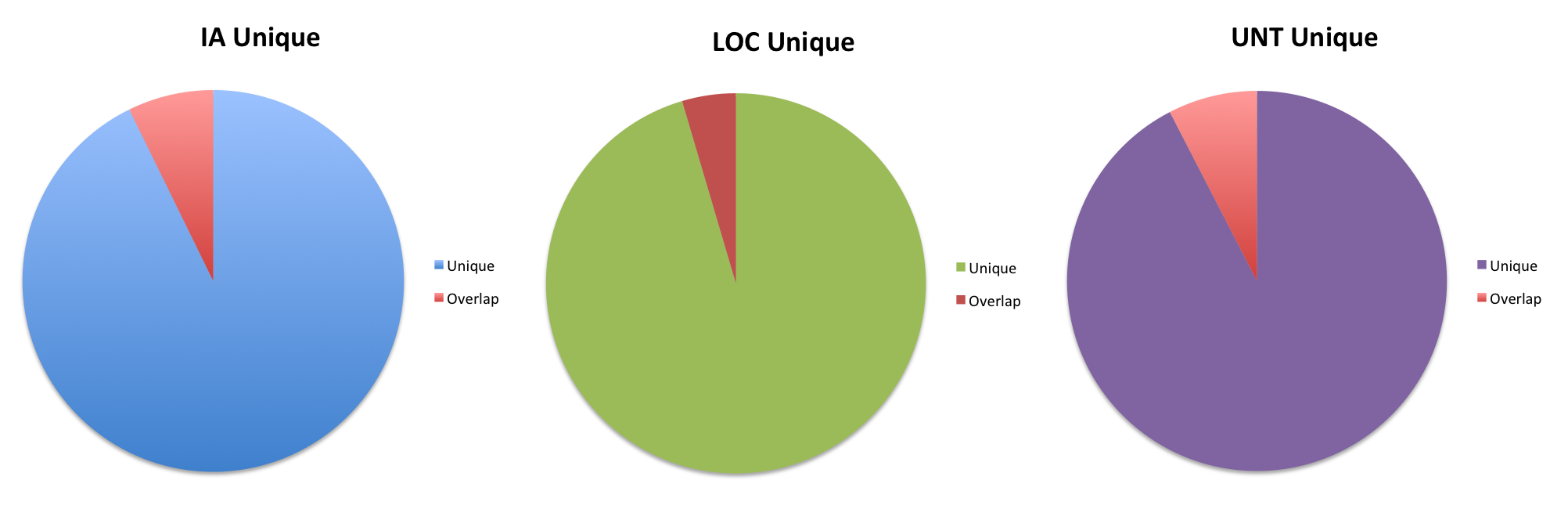
Unique Hashes to one CDX file
Next up was number of hashes that were unique to a collecting organizations CDX file. This took two steps, first I took the difference of two hash sets, took that resulting set and took the difference from the third set.
| Collecting Org | Unique Hashes | Unique to Collecting Org | Percentage Unique |
| IA | 45,487,147 | 42,187,799 | 92.70% |
| LOC | 50,835,632 | 48,510,991 | 95.40% |
| UNT | 25,179,867 | 23,269,009 | 92.40% |
Unique to a collecting org
It appears that there is quite a bit of unique content in each of the CDX files. With over 92% or more of the content being unique to the collecting organization.
Common between two but not three CDX files
The final question to answer was how much of the content is shared between two collecting organizations but not present in the third’s contribution.
| Shared by: | Unique Hashes |
| Shared by IA and LOC but not UNT | 1,737,980 |
| Shared by IA and UNT but not LOC | 1,324,197 |
| Shared by UNT and LOC but not IA | 349,490 |
Closing
Unique and shared hashes
Based on this brief look at how content hashes are distributed across the three CDX files that make up the EOT2012 archive, I think a takeaway is that there is very little overlap between the crawling that these three organizations carried out during the EOT harvests. Essentially 97% of content hashes are present in just one repository.
I don’t think this tells all of the story though. There are quite a few caveats that need to be taken into account. First of all this only takes into account the content hashes that are included in the CDX files. If you crawl a dynamic webpage and it prints out the time each time you visit the page, you will get a different content hash. So “unique” is only in the eyes of the hash function that is used.
There are quite a few other bits of analysis that can be done with this data, hopefully I’ll get around to doing a little more in the next few weeks.
If you have questions or comments about this post, please let me know via Twitter.