In my previous post I mentioned that I was starting to take a look at the descriptive metadata fields in the metadata collected and hosted by the Digital Public Library of America. That last post focused on records, how many records had description fields present, and how many were missing. I also broke those numbers into the Provider/Hub groupings present in the DPLA dataset to see if there were any patterns.
Moving on the next thing I wanted to start looking at was data related to each instance of the description field. I parsed each of the description fields, calculated a variety of statistics using that description field and then loaded that into my current data analysis tool, Solr which acts as my data store and my full-text index.
After about seven hours of processing I ended up with 17,884,946 description fields from the 11,654,800 records in the dataset. You will notice that we have more descriptions than we do records, this is because a record can have more than one instance of a description field.
Lets take a look at a few of the high-level metrics.
Cardinality
I first wanted to find out the cardinality of the lengths of the description fields. When I indexed each of the descriptions, I counted the number of characters in the description and saved that as an integer in a field called desc_length_i in the Solr index. Once it was indexed, it was easy to retrieve the number of unique values for length that were present. There are 5,287 unique description lengths in the 17,884,946 descriptions that were are analyzing. This isn’t too surprising or meaningful by itself, just a bit of description of the dataset.
I tried to make a few graphs to show the lengths and how many descriptions had what length. Here is what I came up with.
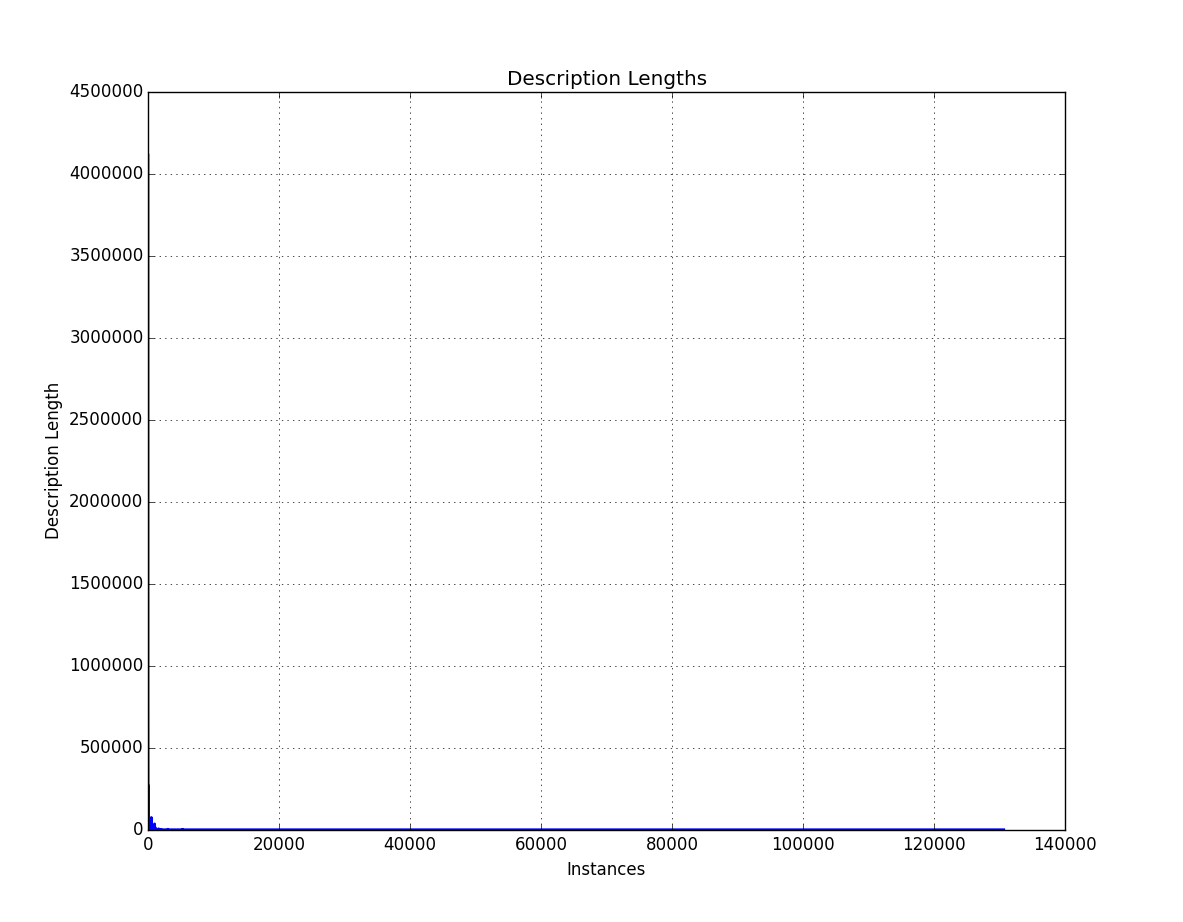
Length of Descriptions in dataset
You can see a blue line barely, the problem is that the zero length records are over 4 million and the longer records are just single instances.
Here is a second try using a log scale for the x axis
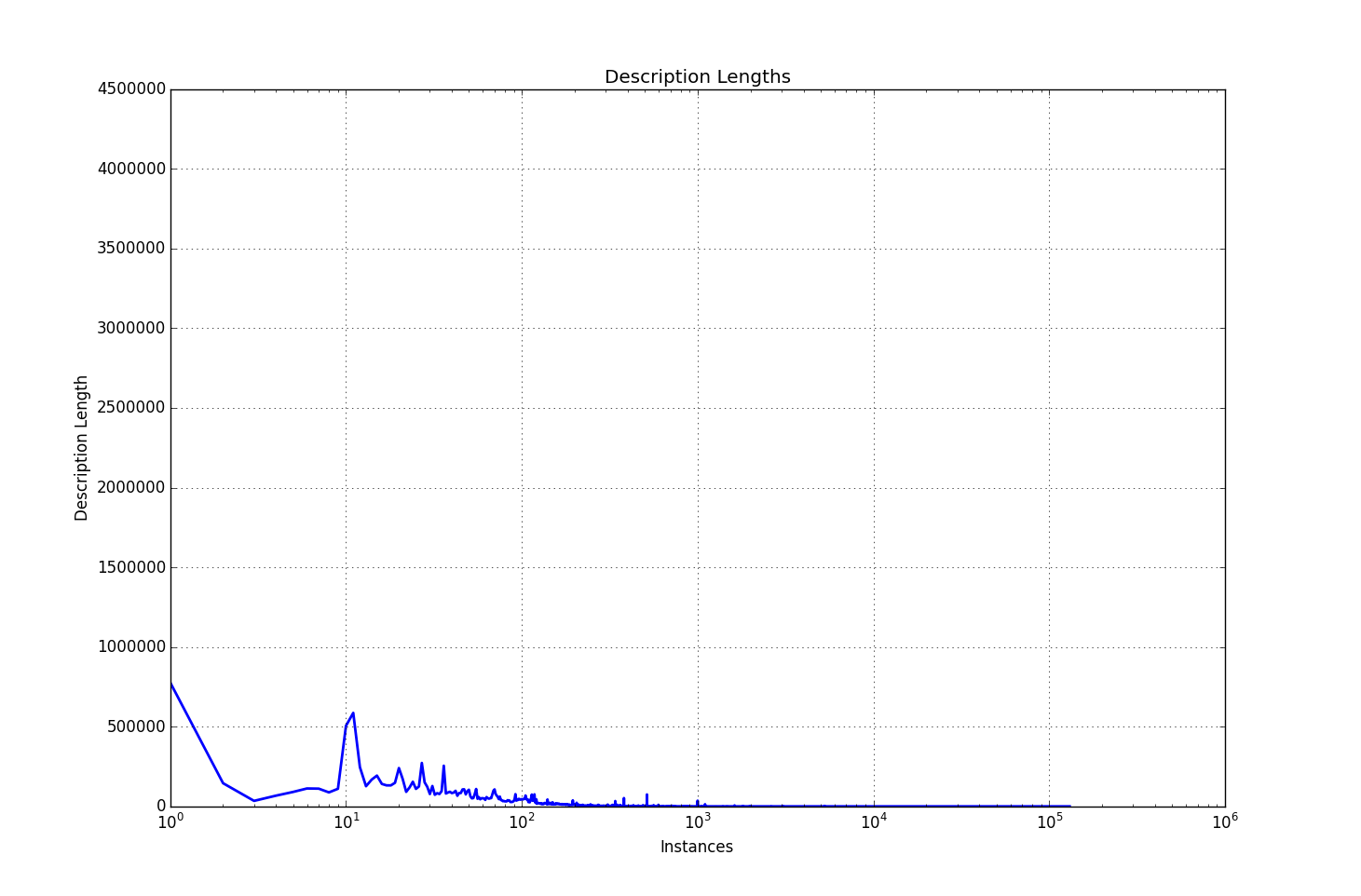
Length of Descriptions in dataset (x axis log)
This reads a little better I think, you can see that there is a dive down from zero lengths and then at about 10 characters long there is a spike up again.
One more graph to see what we can see, this time a log-log plot of the data.
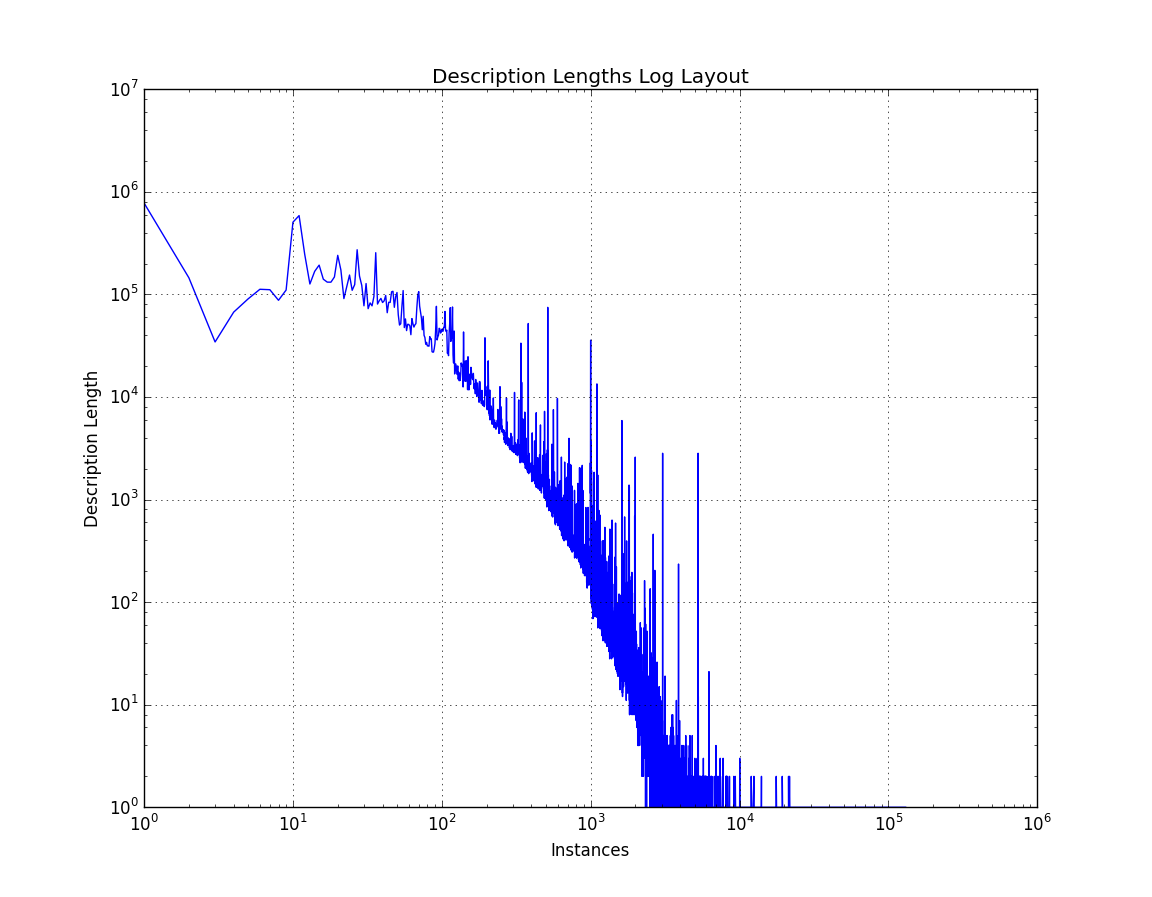
Length of Descriptions in dataset (log-log)
Average Description Lengths
Now that we are finished with the cardinality of the lengths, next up is to figure out what the average description length is for the entire dataset. This time the Solr StatsComponent is used and makes getting these statistics a breeze. Here is a small table showing the output from Solr.
| min | max | count | missing | sum | sumOfSquares | mean | stddev |
| 0 | 130,592 | 17,884,946 | 0 | 1,490,191,622 | 2,621,904,732,670 | 83.32 | 373.71 |
Here we see that the minimum length for a description is zero characters (a record without a description present has a length of zero for that field in this model). The longest record in the dataset is 130,592 characters long. The total number of characters present in the dataset was nearly one and a half billion characters. Finally the number that we were after is the average length of a description, this turns out to be 83.32 characters long.
For those that might be curious what 84 characters (I rounded up instead of down) of description looks like, here is an example.
Aerial photograph of area near Los Angeles Memorial Coliseum, Los Angeles, CA, 1963.
So not a horrible looking length for a description. It feels like it is just about one sentence long with 13 “words” in this sentence.
Long descriptions
Jumping back a bit to look at the length of the longest description field, that description is 130,592 characters long. If you assume that the average single spaced page is 3,000 characters long, this description field is 43.5 pages long. The reader of this post that has spent time with aggregated metadata will probably say “looks like someone put the full-text of the item into the record”. If you’ve spent some serious (or maybe not that serious) time in the metadata mines (trenches?) you would probably mumble somethings like “ContentDM grumble grumble” and you would be right on both accounts. Here is the record on the DPLA site with the 130,492 character long description – http://dp.la/item/40a4f5069e6bf02c3faa5a445656ea61
The next thing I was curious about was the number of descriptions that were “long”. To answer this I am going to require a little bit of back of the envelope freedom right now to decide what “long” is for a description field in a metadata record. (In future blog posts I might be able to answer this with different analysis on the data but this hopefully will do for today.) For now I’m going to arbitrarily decide that anything over 325 characters in length is going to be considered “too long”.
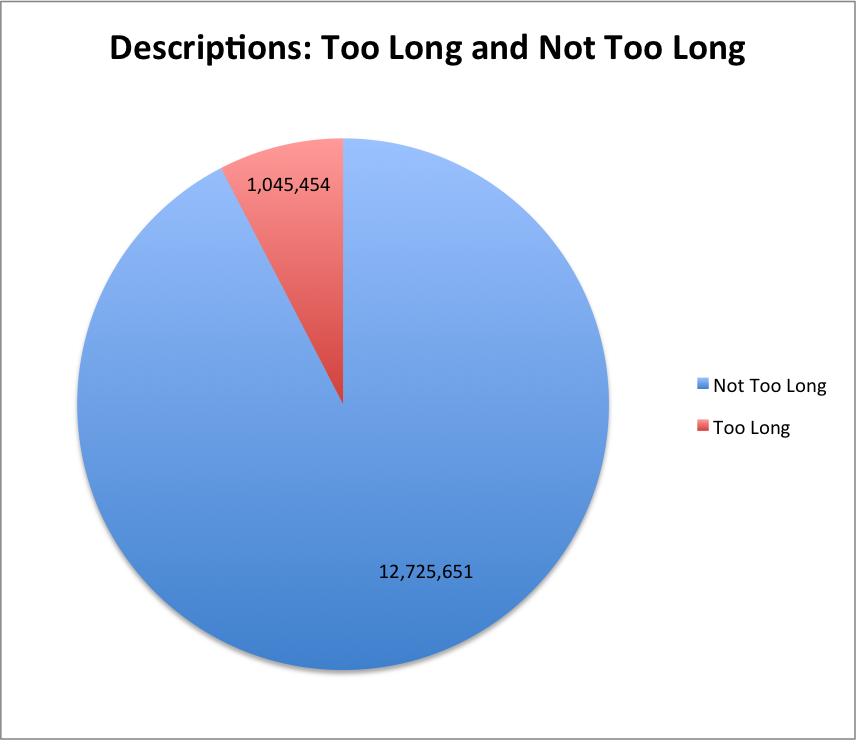
Descriptions: Too Long and Not Too Long
Looking at that pie chart, there are 5.8% of the descriptions that are “too long” based on my ad-hoc metric from above. This 5.8% of the records make up 708,050,671 or 48% of the 1,490,191,622 characters in the entire dataset. I bet if you looked a little harder you would find that the description field gets very close to the 80/20 rule with 20% of the descriptions accounting for 80% of the overall description length.
Short descriptions
Now that we’ve worked with long descriptions, the next thing we should look at are the number of descriptions that are “short” in length.
There are 4,113,841 records that don’t have a description in the DPLA dataset. This means that for this analysis 4,113,841(23%) of the descriptions have a length of 0. There are 2,041,527 (11%) descriptions that have a length between 1 and 10 characters in length. Below is the breakdown of these ten counts, you can see that there is a surprising number (777,887) of descriptions that have a single character as their descriptive contribution to the dataset.
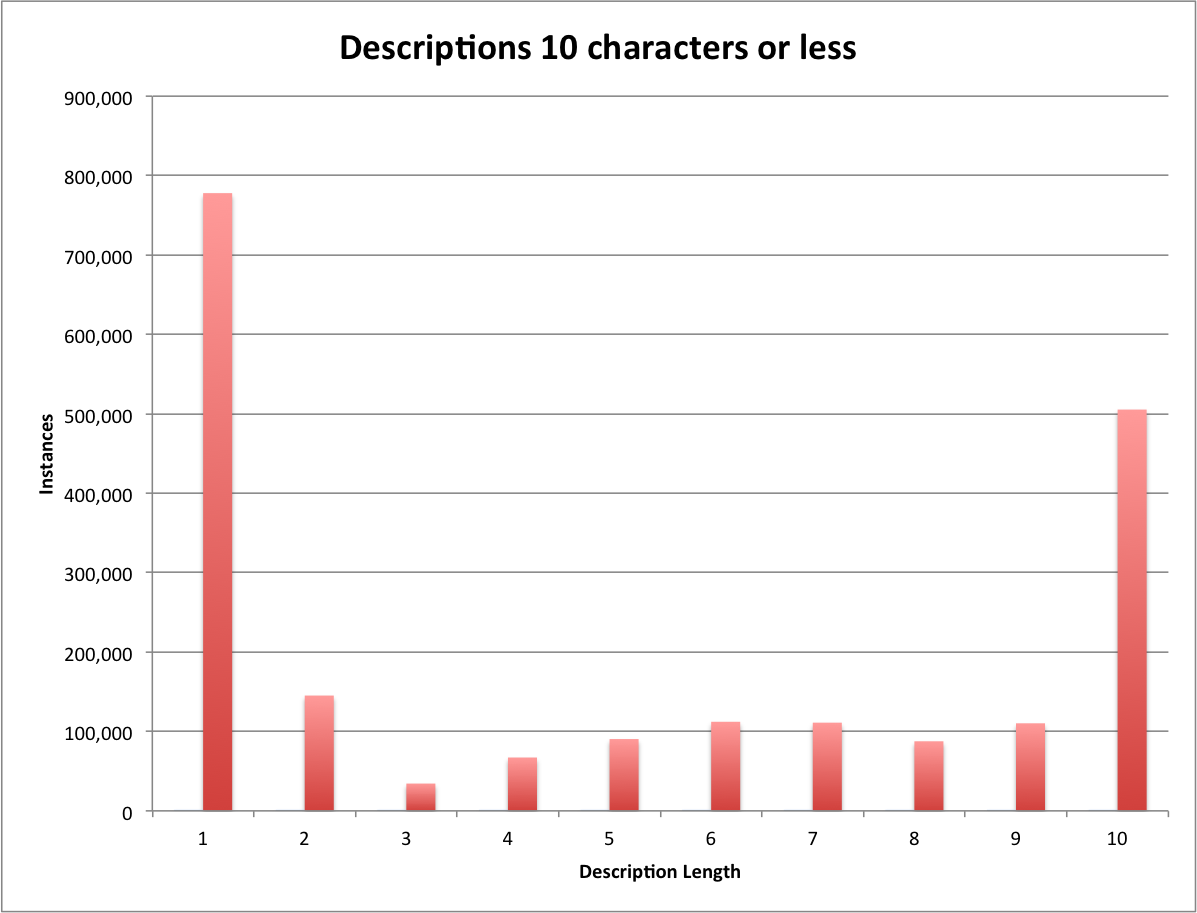
Descriptions 10 characters or less
There is also an interesting spike at ten characters in length where suddenly we jump to over 500,000 descriptions in the DPLA.
So what?
Now that we have the average length of a description in the DPLA dataset, the number of records that we consider “long” and the number of records that we consider “short”. I think the very next question that gets asked is “so what?”
I think there are four big reasons that I’m working on this kind of project with the DPLA data.
One is that the DPLA is the largest aggregation of descriptive metadata in the US for digital resources in cultrual heritage institutions. This is important because you get to take a look at a wide variety of data input rules, practices, and conversions from local systems to an aggregated metadata system.
Secondly this data is licensed with a CC0 license and in a bulk data format so it is easy to grab the data and start working with it.
Thirdly there haven’t been that many studies on descriptive metadata like this that I’m aware of. OCLC will publish analysis on their MARC catalog data from time to time, and the research that was happening at UIUC in the GSILS with IMLS funded metadata isn’t going on anymore (great work to look at by the way) so there really aren’t that many discussions about using large scale aggregations of metadata to understand the practices in place in cultural heritage institutions across the US. I am pretty sure that there is work being carried out across the Atlantic with the Eureopana datasets that are available.
Finally I think that this work can lead to metadata quality assurance practices and indicators for metadata creators and aggregators about what may be wrong with their metadata (a message saying “your description is over a page long, what’s up with that?”).
I don’t think there are many answers so far in this work but I feel that they are moving us in the direction of a better understanding of our descriptive metadata world in the context of these large aggregations of metadata.
If you have questions or comments about this post, please let me know via Twitter.