For a class this last semester I spent a bit of time working with the Library of Congress Name Authority File (LC-NAF) that is available here in a number of downloadable formats.
After downloading the file and extracting only the parts I was interested in, I was left with 7,861,721 names to play around with.
The resulting dataset has three columns, the unique identifier for a name, the category of either PersonalName or CorporateName and finally the authoritative string for the given name.
Here is an example set of entries in the dataset.
<http://id.loc.gov/authorities/names/no2015159973> PersonalName Thomas, Mike, 1944- <http://id.loc.gov/authorities/names/n00004656> PersonalName Gutman, Sharon A. <http://id.loc.gov/authorities/names/no99024929> PersonalName Hornby, Lester G. (Lester George), 1882-1956 <http://id.loc.gov/authorities/names/n86050616> PersonalName Borisi\uFE20u\uFE21k, G. N. (Galina Nikolaevna) <http://id.loc.gov/authorities/names/no2011132525> PersonalName Cope, Samantha <http://id.loc.gov/authorities/names/nr92002092> PersonalName Okuda, Jun <http://id.loc.gov/authorities/names/n2008028760> PersonalName Brandon, Wendy <http://id.loc.gov/authorities/names/no2008088468> PersonalName Gminder, Andreas <http://id.loc.gov/authorities/names/nb2013005548> CorporateName Archivo Hist\u00F3rico Provincial de Granada <http://id.loc.gov/authorities/names/n84081250> PersonalName Mermier, Pierre-Marie, 1790-1862
I was interested in how Personal and Corporate names differ across the whole LC-NAF file and to see if there were any patterns that I could tease out. The final goal if I could train a classifier to automatically classify a name string into either PersonalName or CorporateName classes.
But more on that later.
Personal or Corporate Name
The first thing to take a look at in the dataset is the split between PersonalName and CorporateName strings.
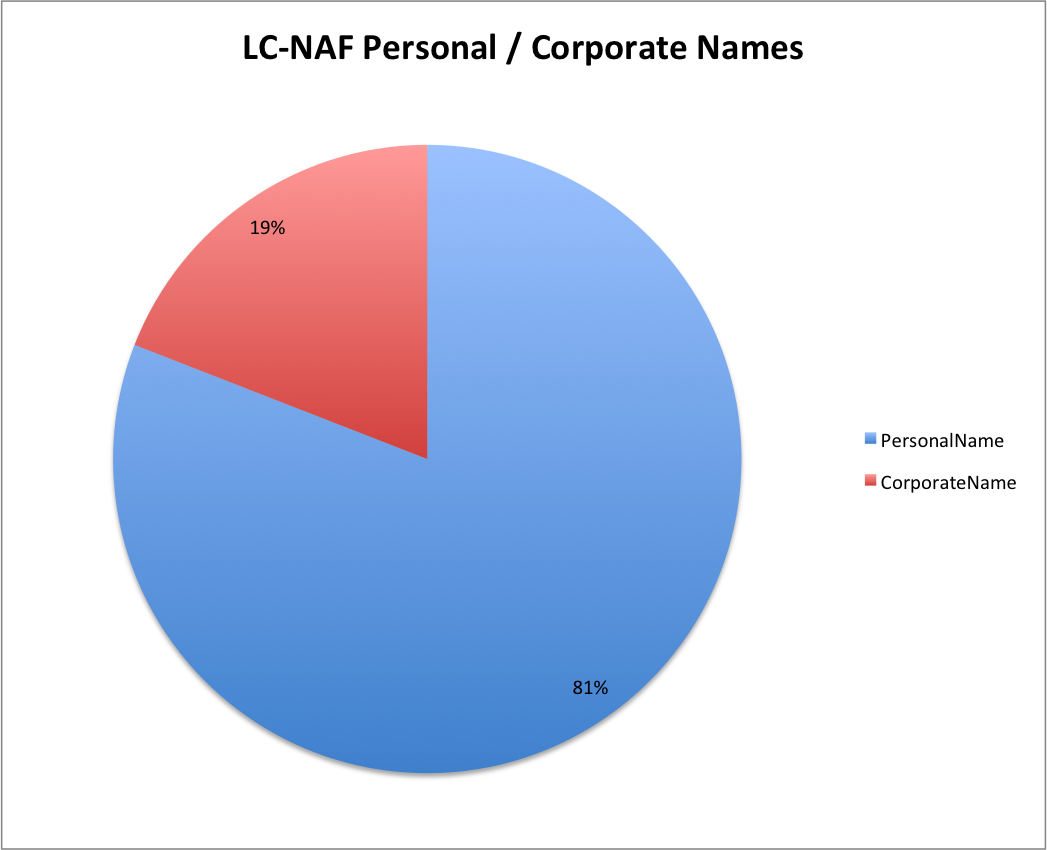
LC-NAF Personal / Corporate Name Distribution
As you can see the majority of names in the LC-NAF are personal names with 6,361,899 (81%) and just 1,499,822 (19%) being corporate names.
Commas
One of the common formatting rules in library land is to invert names so that they are in the format of Last, First. This is useful when sorting names as it will group names together by family name instead of ordering them by the first name. Because of this common rule I expected that the majority of the personal names will have a comma. I wasn’t sure what number of the corporate names would have a comma in them.
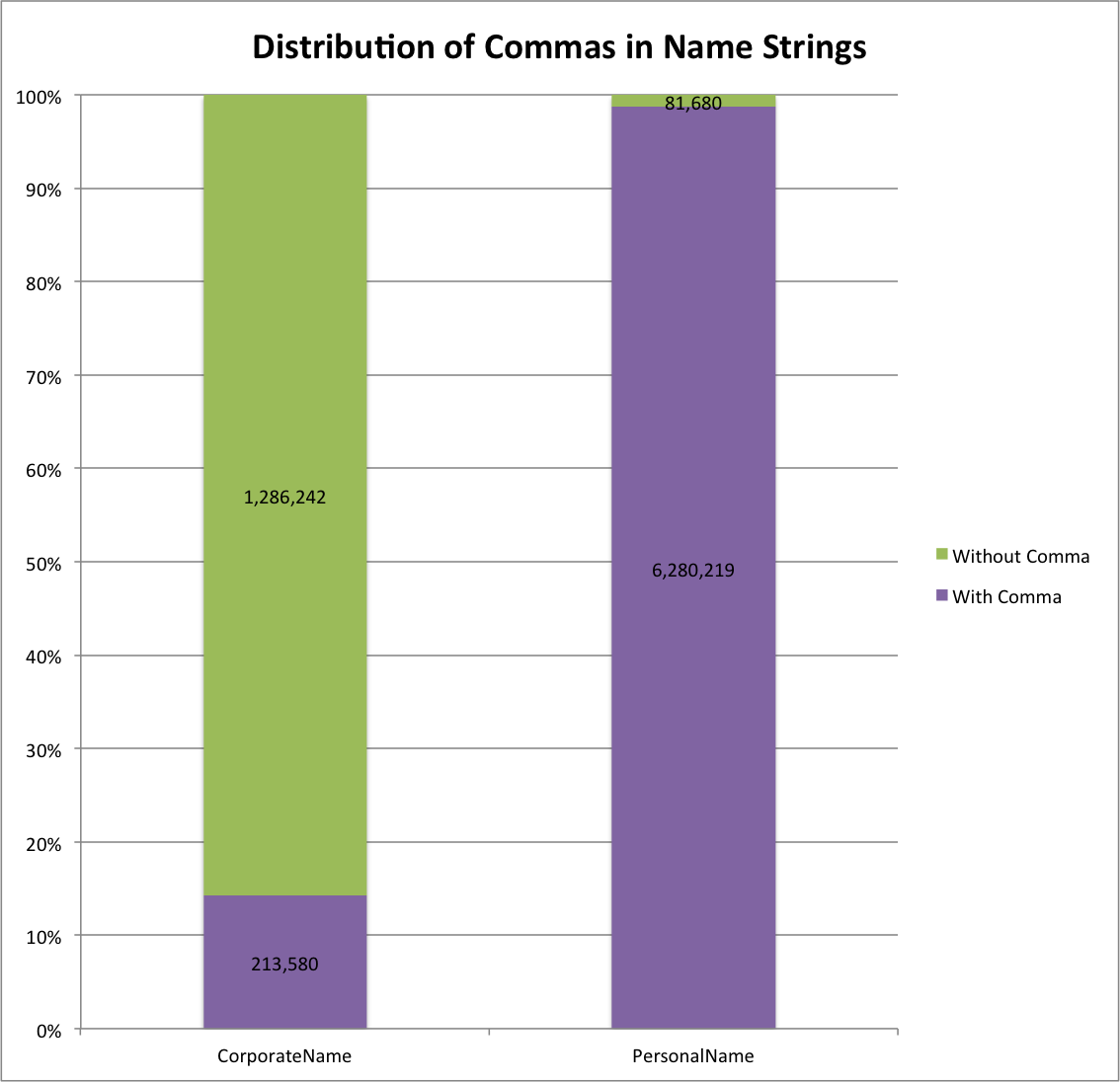
Distribution of Commas in Name Strings
In looking at the graph above you can see that it is true that the majority of personal names have commas 6,280,219 (99%) with a much smaller set of corporate names 213,580 (14%) having a comma present.
Periods
I next took a look at periods in the name string. I wasn’t sure exactly what I would find in doing this so my only prediction was that there would be fewer name strings that have periods present.
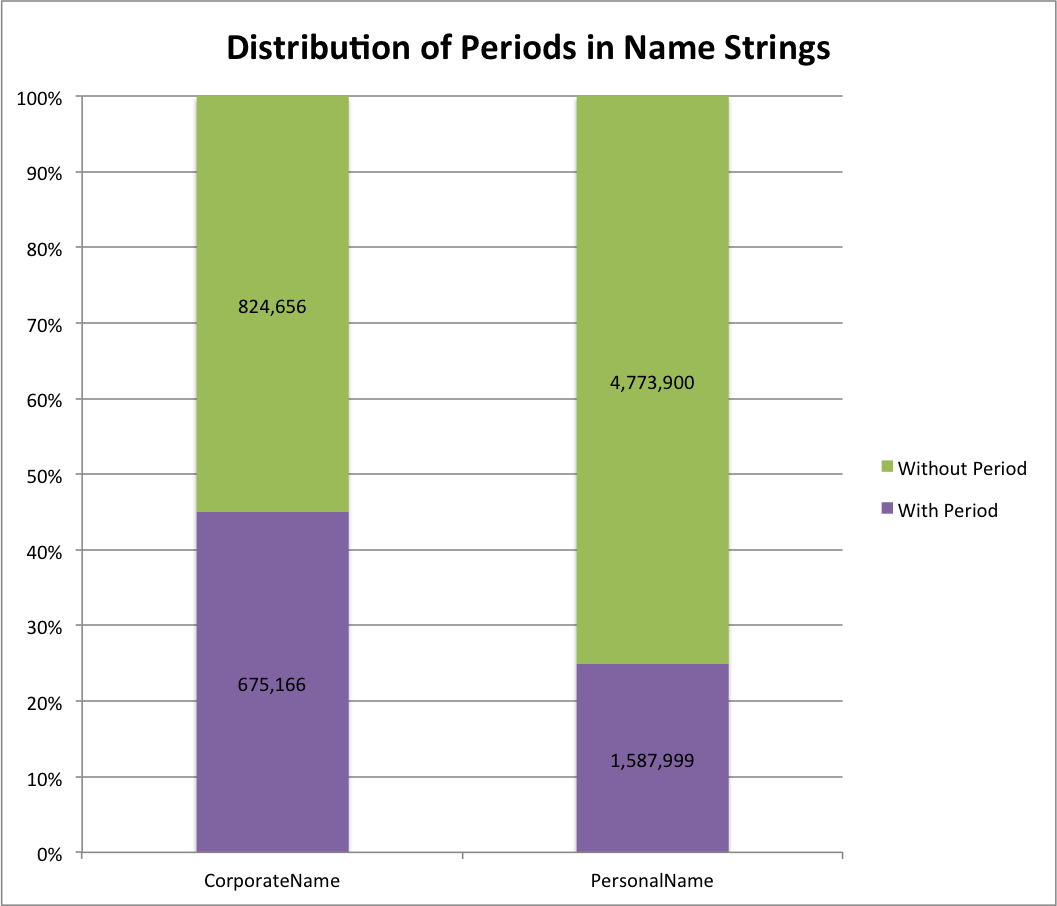
Distribution of Periods in Name Strings
This time we see a bit different graph. Personal names have1,587,999 (25%) instances with periods while corporate names had 675,166 (45%) instances with periods.
Hyphens
Next up to look at are hyphens that occur in name strings.
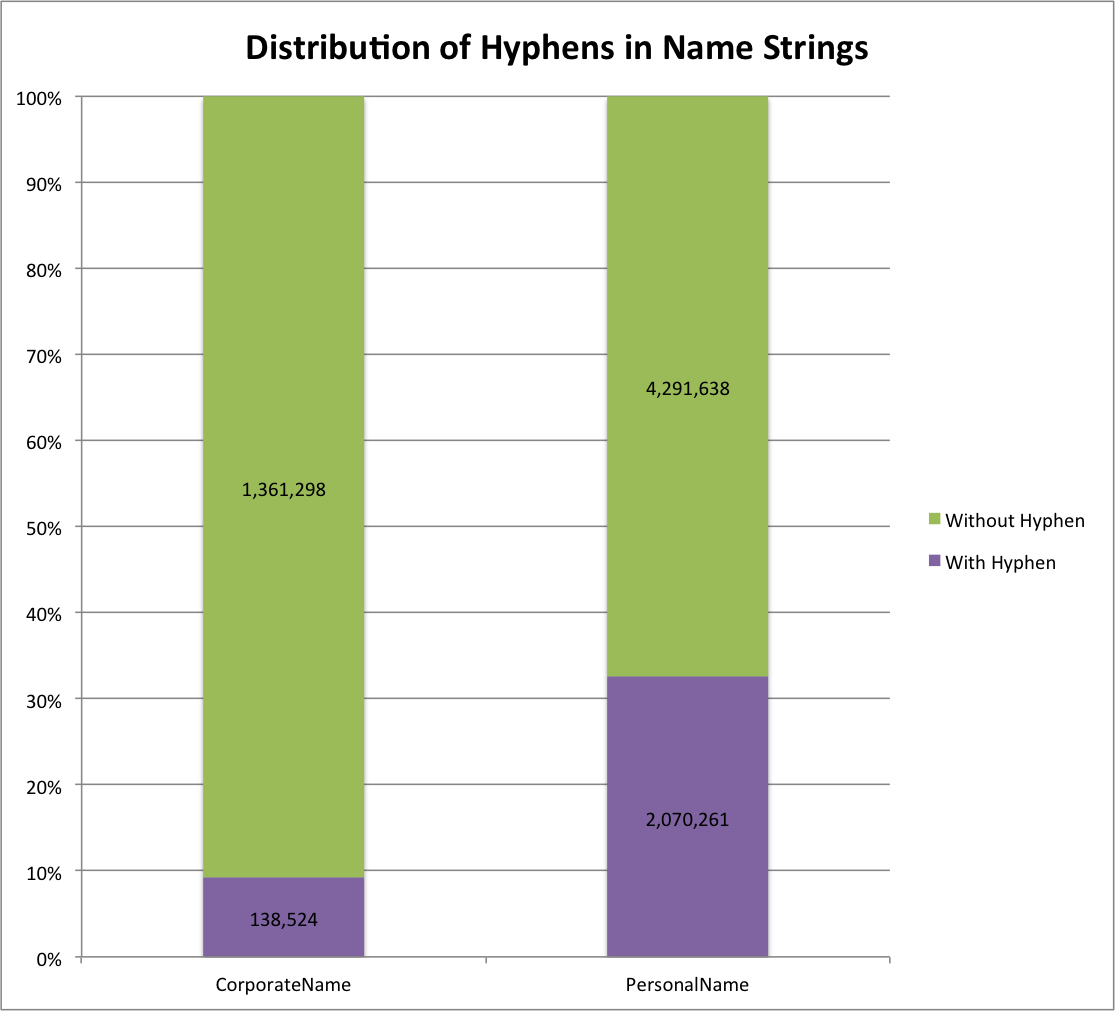
Distribution of Hyphens in Name Strings
There are 138,524 (9%) of corporate names with hyphens and 2,070,261 (33%) of personal names with hyphens present in the name string.
I know that there are many name strings in the LC-NAF that have dates in the format of yyyy-yyyy, yyyy-, or -yyyy. Let’s see how many name strings have a hyphen when we remove those.
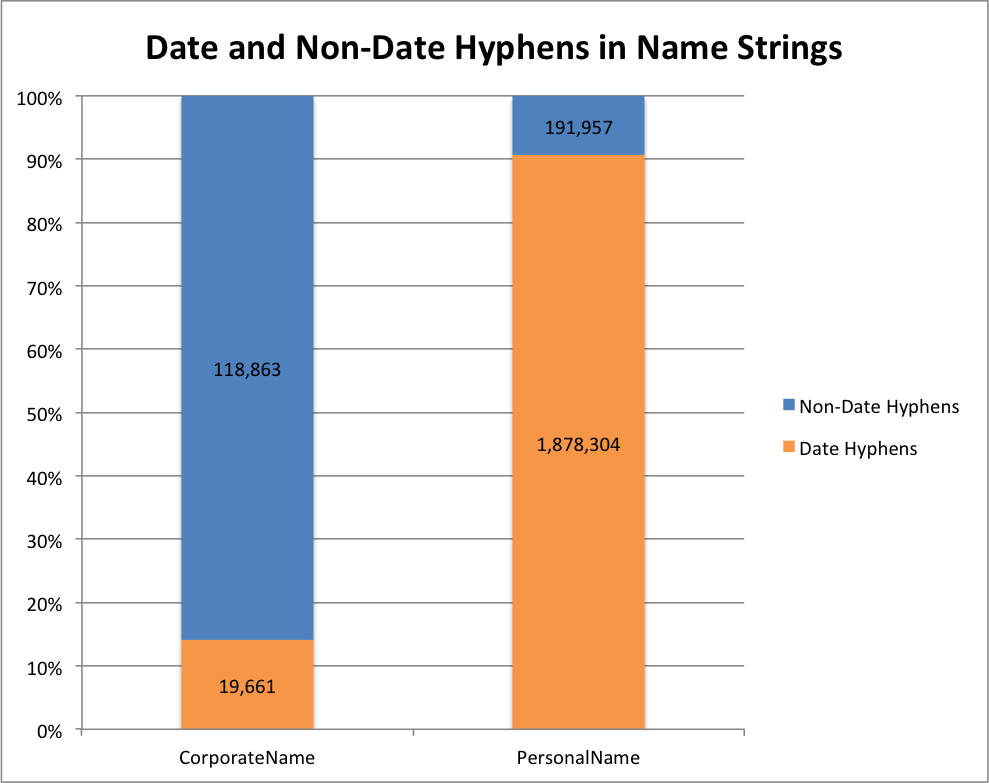
Date and Non-Date Hyphens
This time we look at the instances that just have hyphens and divide them into two categories. “Date Hyphens” and “Non-Date Hyphens”. You can see that most of the corporate name strings have hyphens that are not found in relation to dates. The personal names on the other hand have the majority of hyphens occurring in date strings.
Parenthesis
The final punctuation characters we will look at are parenthesis.
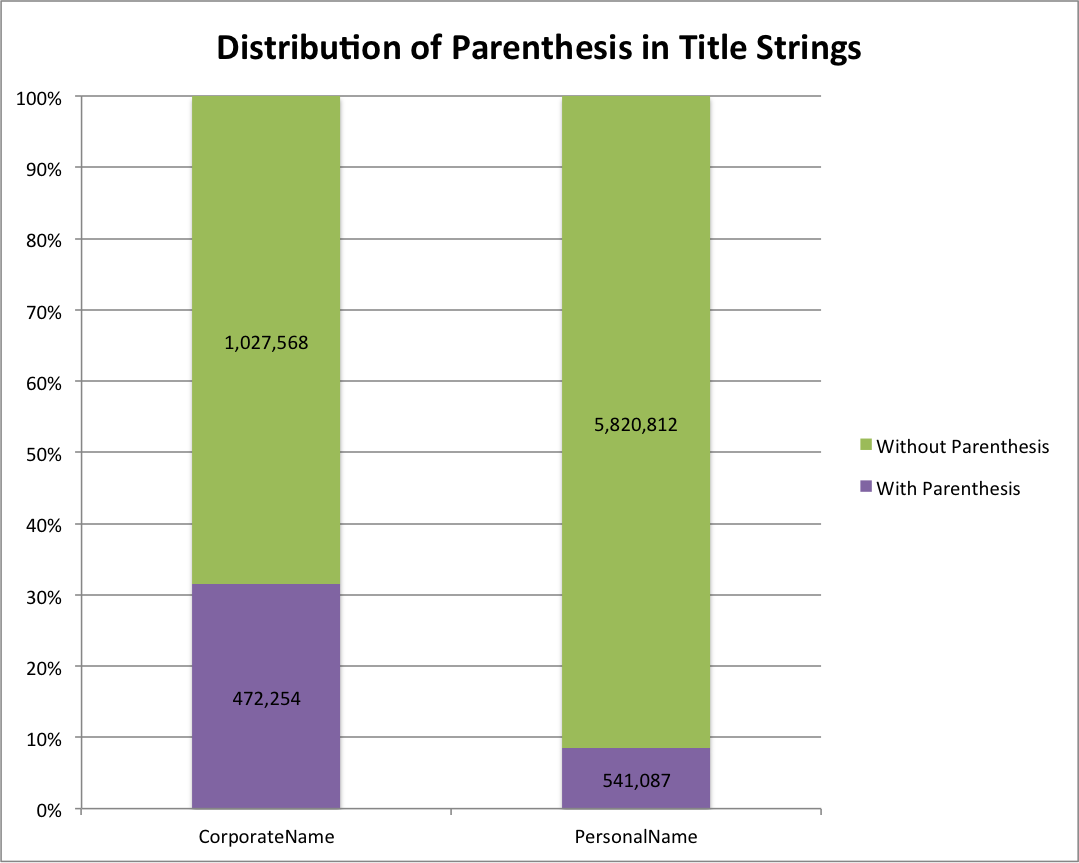
Distribution of Parenthesis in Name Strings
We see that most names overall don’t have parenthesis in them. There are 472,254 (31%) name strings in the dataset with parenthesis. There are also 541,087 (9%) of personal name strings that have parenthesis.
This post is the first in a short series that takes a look at the LC Name Authority File to get a better understanding of how names in library metadata have been constructed over the years.
If you have questions or comments about this post, please let me know via Twitter.