This past week I was clearing out a bunch of software feature request tickets to prepare for a feature push for our digital library system. We are getting ready to do a redesign of The Portal to Texas History and the UNT Digital Library interfaces.
Buried deep in our ticketing system were some tickets made during the past five years that included notes about future implementations that we could create for the system. One of these notes caught my eye because it had the phrase “since date data is so poor in the system”. At first I had dismissed this phrase and ticket altogether because our ideas related to the feature request had changed, but later that phrase stuck with me a bit.
I began to wonder, “what is the quality of our date data in our digital library” and more specifically “what does the date resolution look like across the UNT Libraries’ Digital Collections”.
Getting the Data
The first thing to do was to grab all of the date data for each record in the system. At the time of writing there were 1,310,415 items in the UNT Libraries Digital Collections. I decided the easiest way to grab the date information for these records was to pull it from our Solr index.
I constructed a solr query that would return the value of our dc_date field, the ark identifier we use to uniquely identify each item in the repository, and finally which of the systems (Portal, Digital Library, or Gateway) a record belongs to.
I pulled these as JSON files with 10,000 records per request, did 132 requests and I was in business.
I wrote a short Python little script that takes those Solr responses and converts them into a tab separated format that looks like this:
ark:/67531/metapth2355 1844-01-01 PTH ark:/67531/metapth2356 1845-01-01 PTH ark:/67531/metapth2357 1845-01-01 PTH ark:/67531/metapth2358 1844-01-01 PTH ark:/67531/metapth2359 1844-01-01 PTH ark:/67531/metapth2360 1844 PTH ark:/67531/metapth2361 1845-01-01 PTH ark:/67531/metapth2362 1883-01-01 PTH ark:/67531/metapth2363 1844 PTH ark:/67531/metapth2365 1845 PTH
Next I wrote another Python script that classifies a date into the following categories:
- Day
- Month
- Year
- Other-EDTF
- Unknown
- None
Day, Month, and Year are the three units that I’m really curious about, I identified these with simple regular expressions for yyyy-mm-dd, yyyy-mm, and yyyy respectively. For records that had date strings that weren’t day, month, or year, I checked if the string was an Extended Date Time Format string. If it was valid EDTF I marked it as Other-EDTF, if it wasn’t a valid EDTF and wasn’t a day, month, year I marked it as Unknown. Finally if there wasn’t a date present for a metadata record at all, it is marked as “None”.
One thing to note about the way I’m doing the categories, I am probably missing quite a few values that have day, month or years somewhere in the string by not parsing the EDTF and Unknown strings a little more liberally for days, months and years. This is true but for what I’m trying to accomplish here, I think we will let that slide.
What does the data look like?
The first thing for me to do was to see how many of the records had date strings compared to the number of records that do not have date strings present.
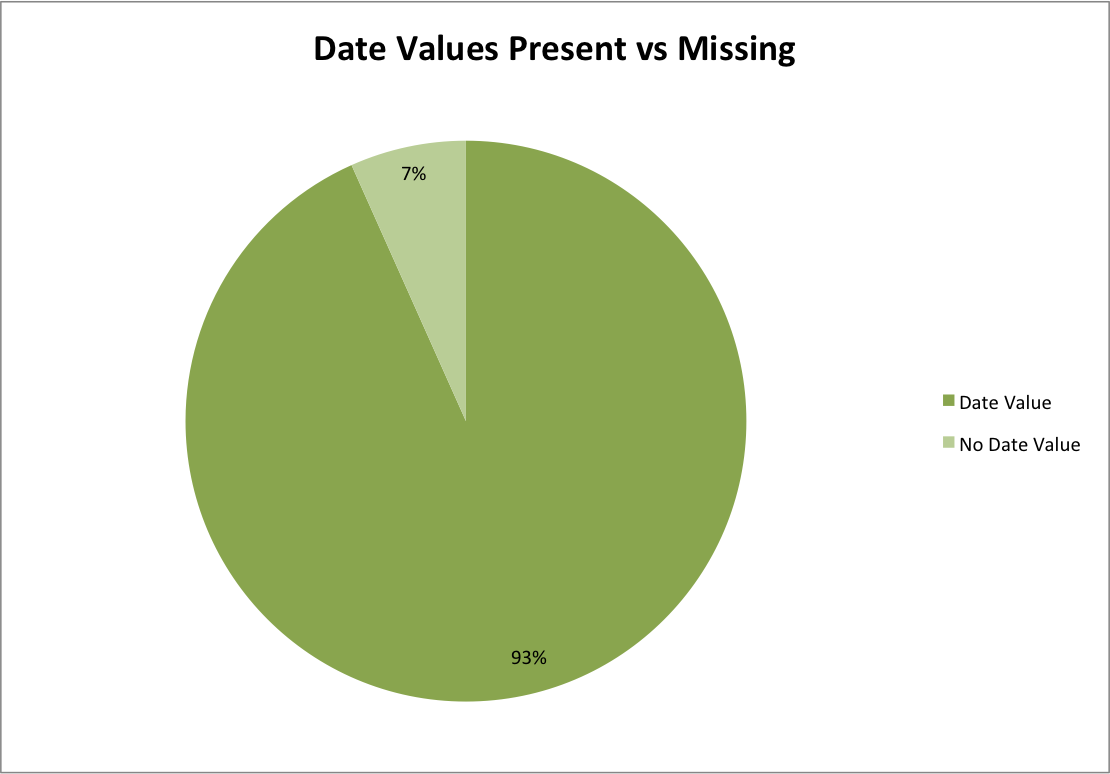
Date values vs none
Looking at the numbers shows 1,222,750 (93%) of records having date strings and 87,665 (7%) are missing date strings. Just with those numbers I think that we negate the statement that “date data is poor in the system”. But maybe just the presence of dates isn’t what the ticket author meant. So we investigate further.
The next thing I did was to see how many of the dates overall were able to be classified as a day, month, or year. The reasoning for looking at these values is that you can imagine building user interfaces that make use of date values to let users refine their searching activities or browse a collection by date.
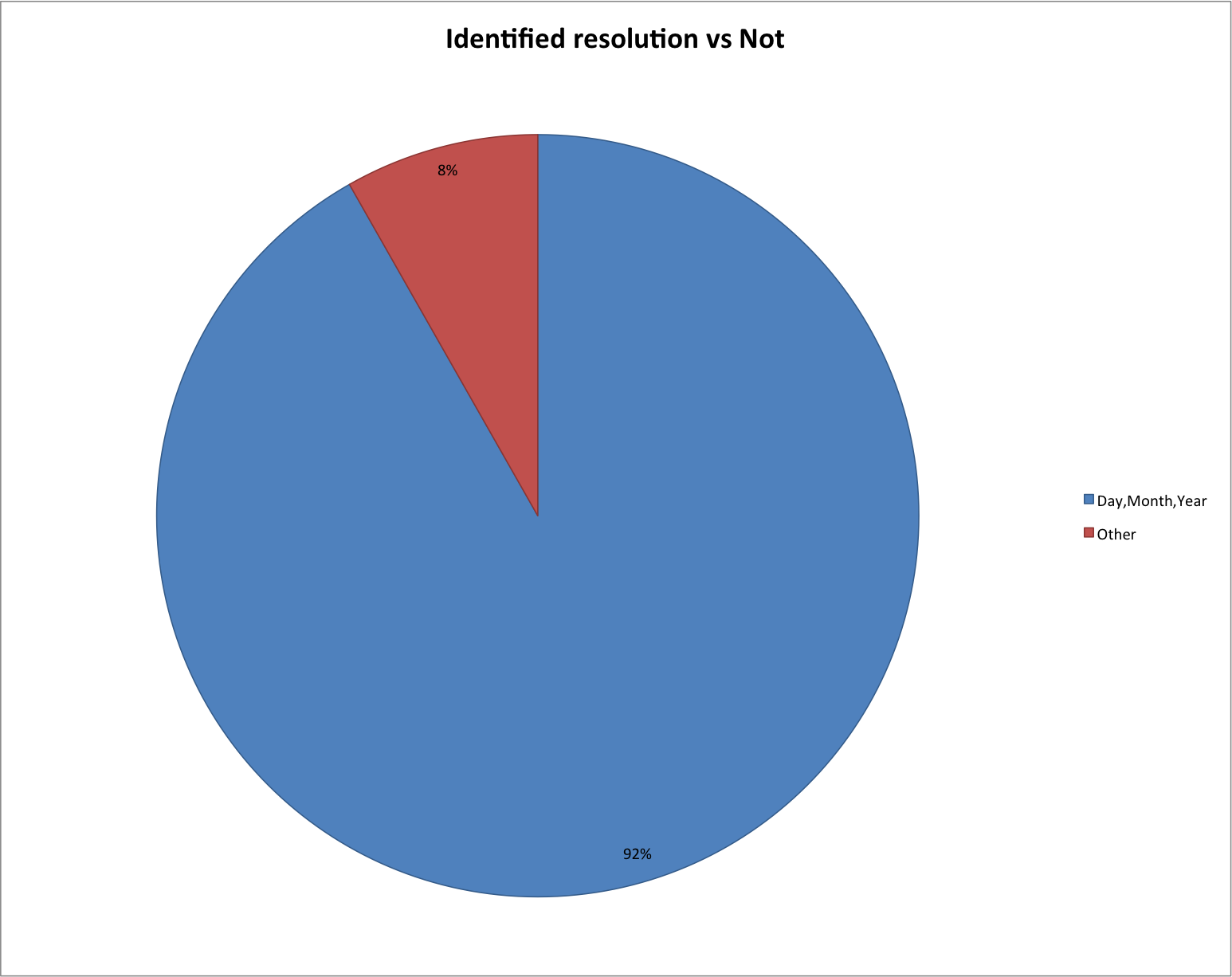
Identified Resolution vs Not
This chart shows that the overwhelming majority of objects in our digital library 1,202,625 (92%) had date values that were either day, month, or year and only 107,790 (8%) were classified as “Other”. Now this I think does blow the statement about poor date data quality away.
The last thing I think there is to look at is how each of the categories stack up against each other. Once again, a pie chart.
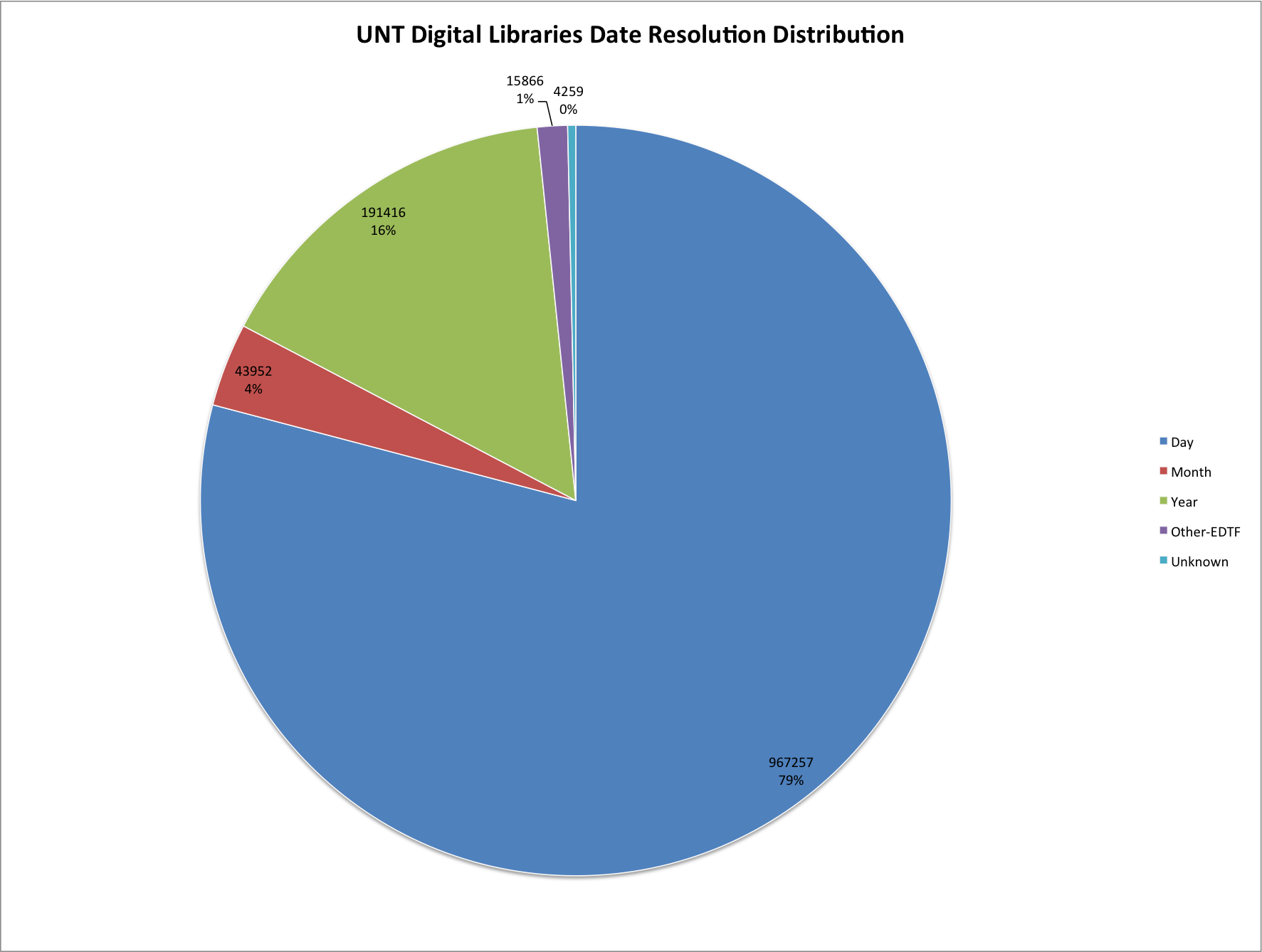
UNT Digital Libraries Date Resolution Distribution
Here is a table view of the same data.
| Date Classification | Instances | Percentage |
| Day | 967,257 | 73.8% |
| Month | 43,952 | 3.4% |
| Year | 191,416 | 14.6% |
| Other-EDTF | 15,866 | 1.2% |
| Unknown | 4,259 | 0.3% |
| None | 87,665 | 6.7% |
So looking at this data it is clear that the majority of our digital objects have the resolution at the “day” level with 967,257 records or 73.8% of all records being in the format yyyy-mm-dd. Next year resolution is the second highest occurrence with 191,416 or 14.6%. Finally Month resolution came in with 43,952 records or 3.4%. There were 15,866 records that had valid EDTF values, 4,259 with other date values and finally the 87,665 records that did not contain a data at all.
Conclusion
I think that I can safely say that we do in fact have a large amount of date data in our digital libraries. This date data can be parsed easily into day, month and year buckets for use in discovery interfaces, and by doing very basic work with the date strings we are able to account for 92% of all records in the system.
I’d be interested to see how other digital libraries stand on date data to see if we are similar or different as far as this goes. I might hit up my colleagues at the University of Florida because their University of Florida Digital Collections is of similar scale with similar content. If you would like to work to compare your digital libraries’ date data let me know.
Hope you enjoyed my musings here, if you have thoughts, suggestions, or if I missed something in my thoughts, please let me know via Twitter.