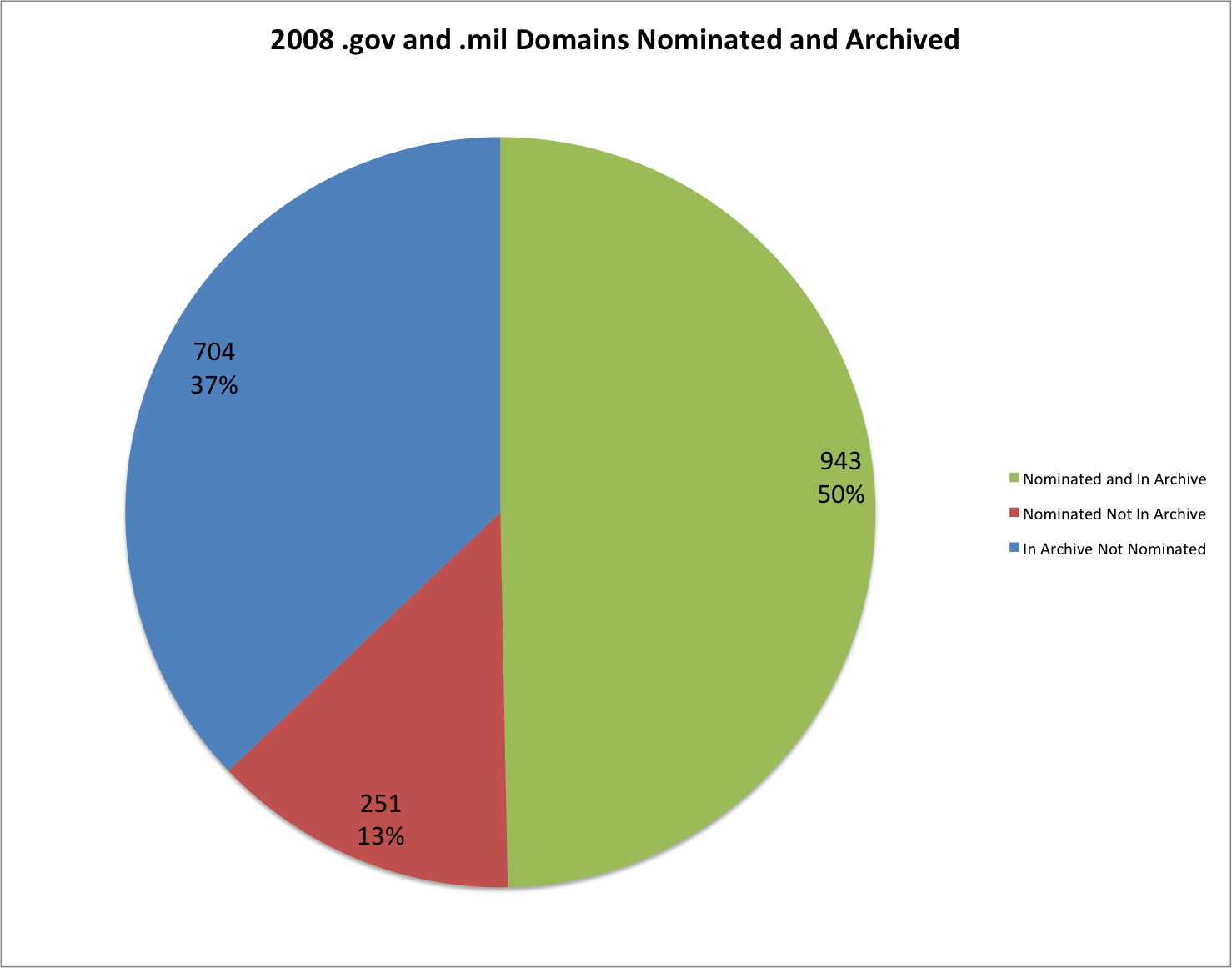
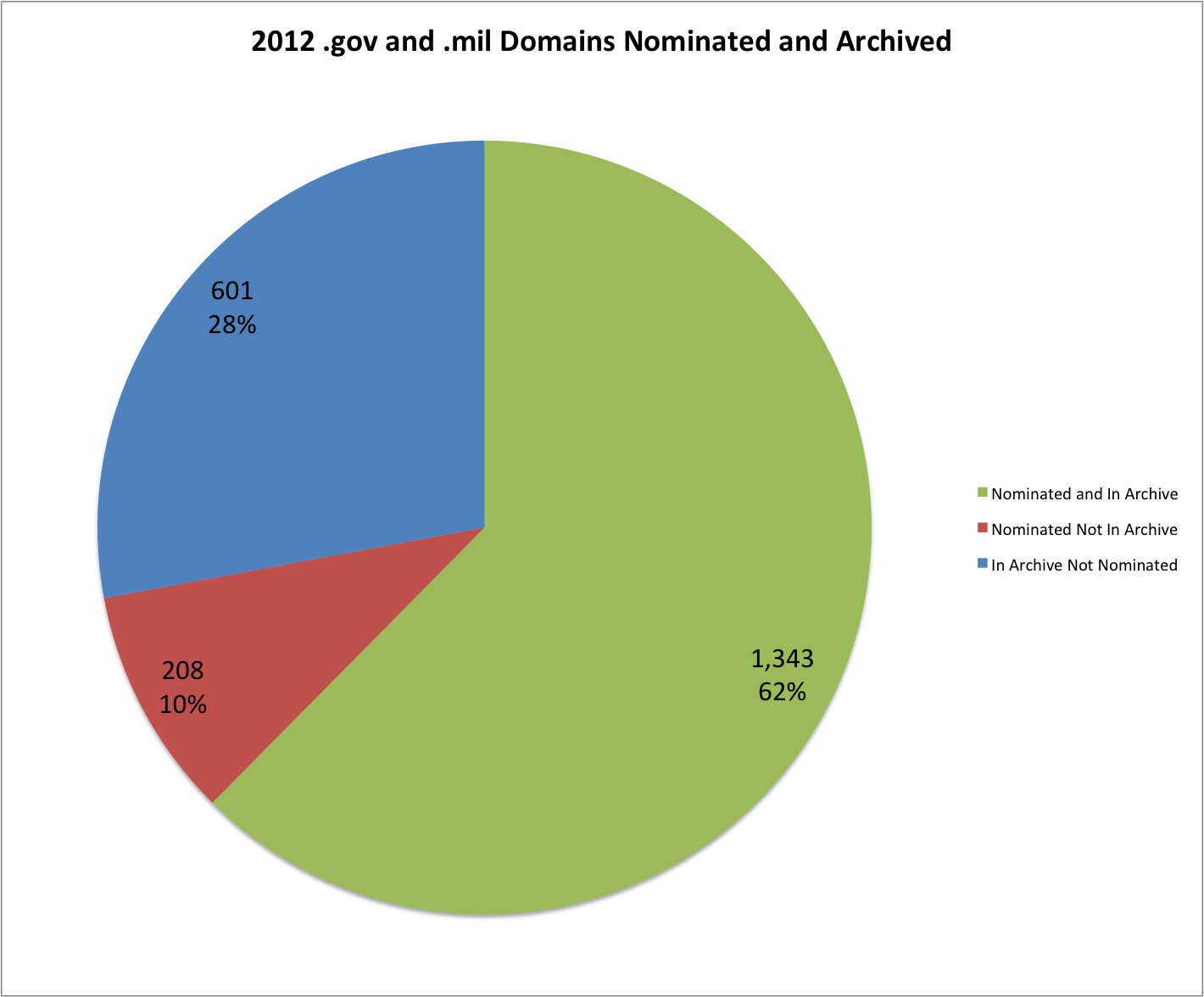
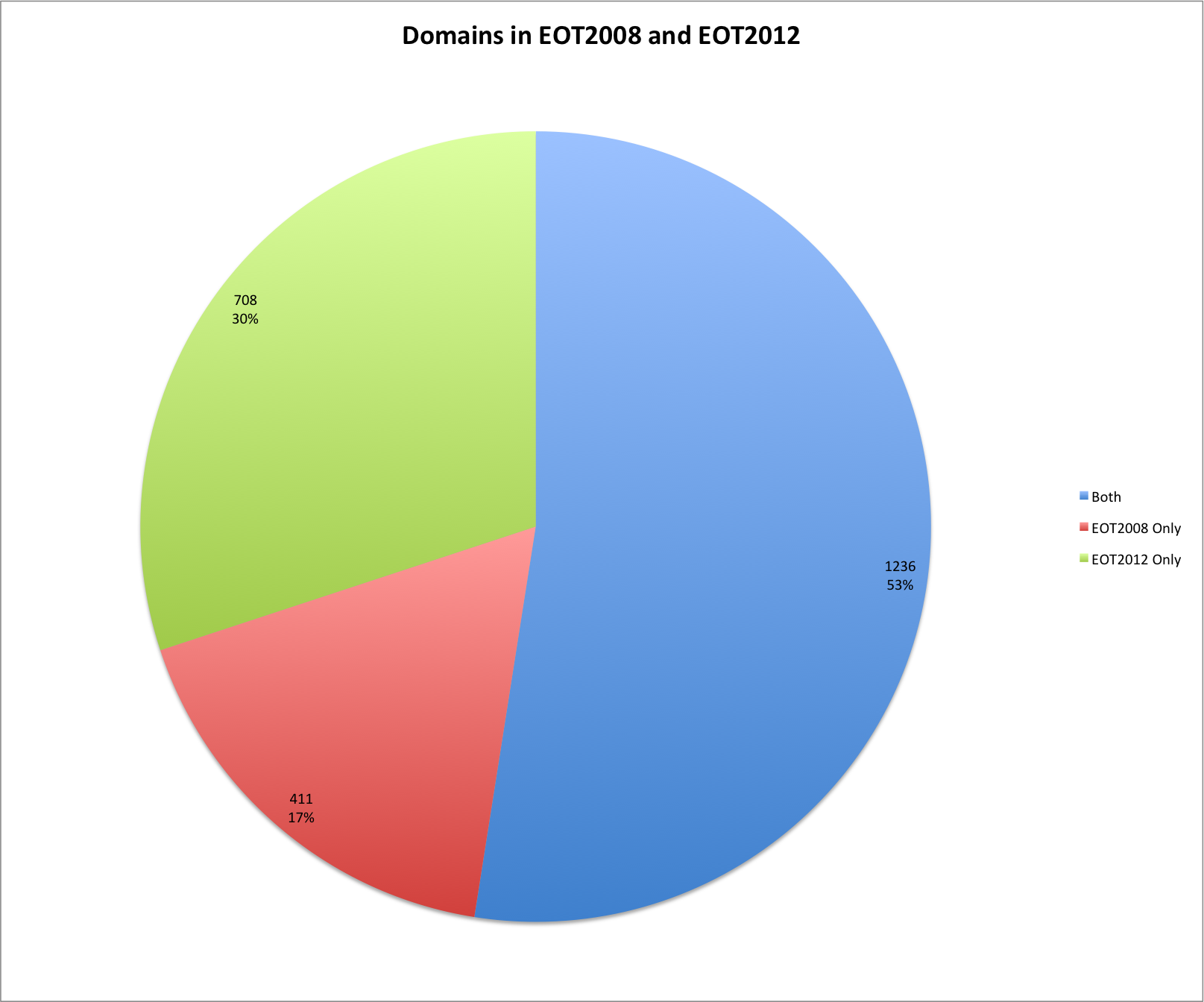
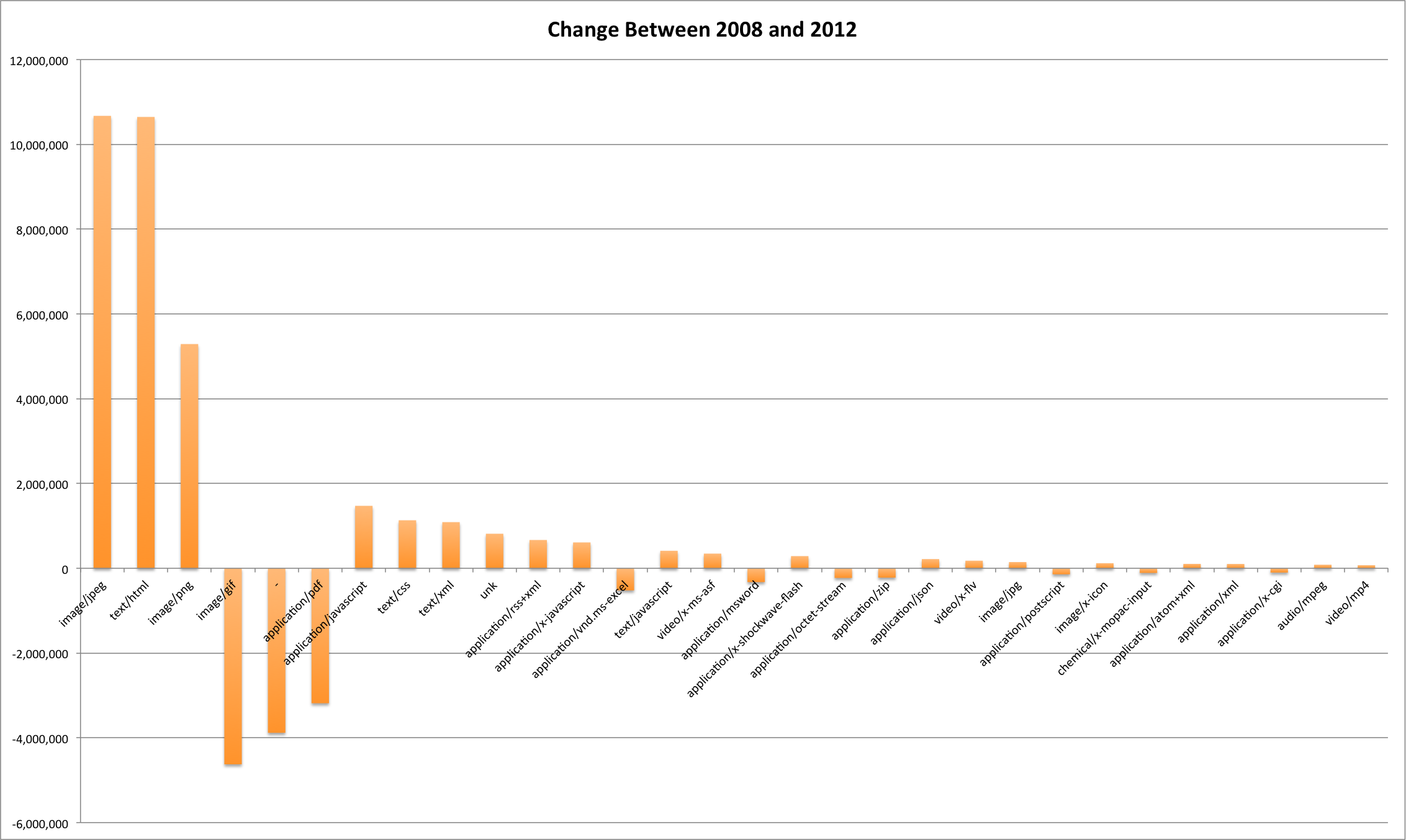
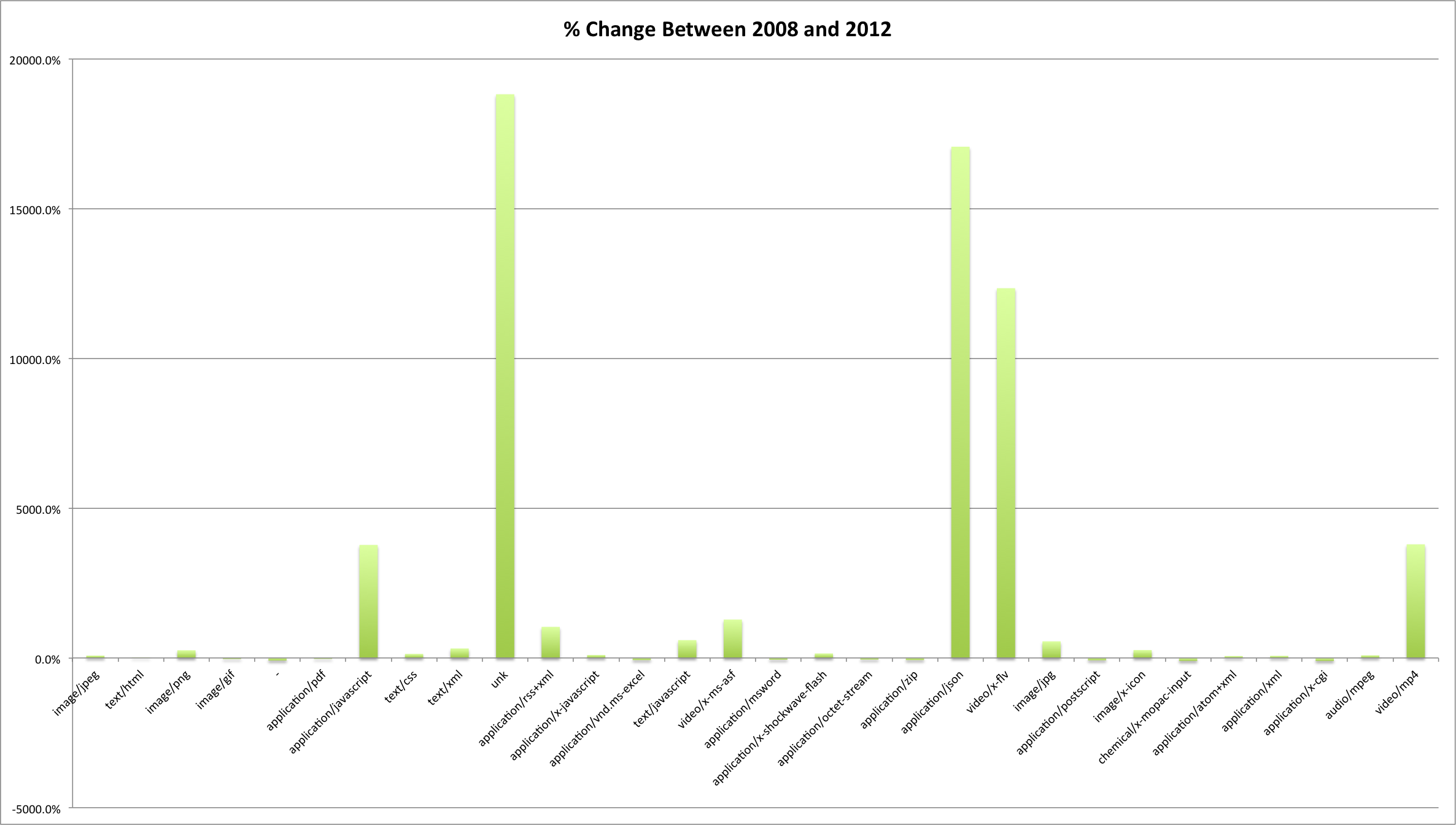
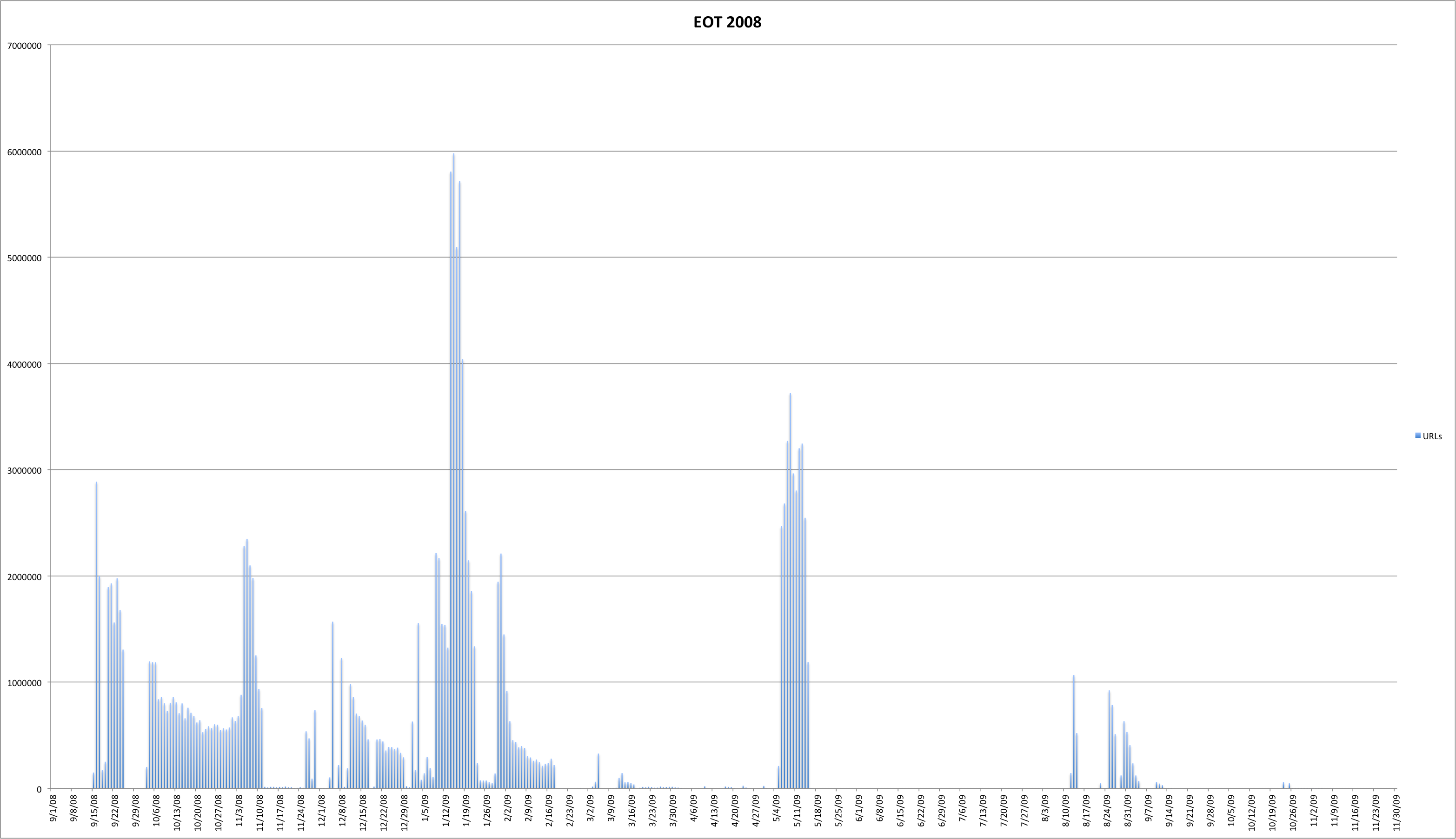
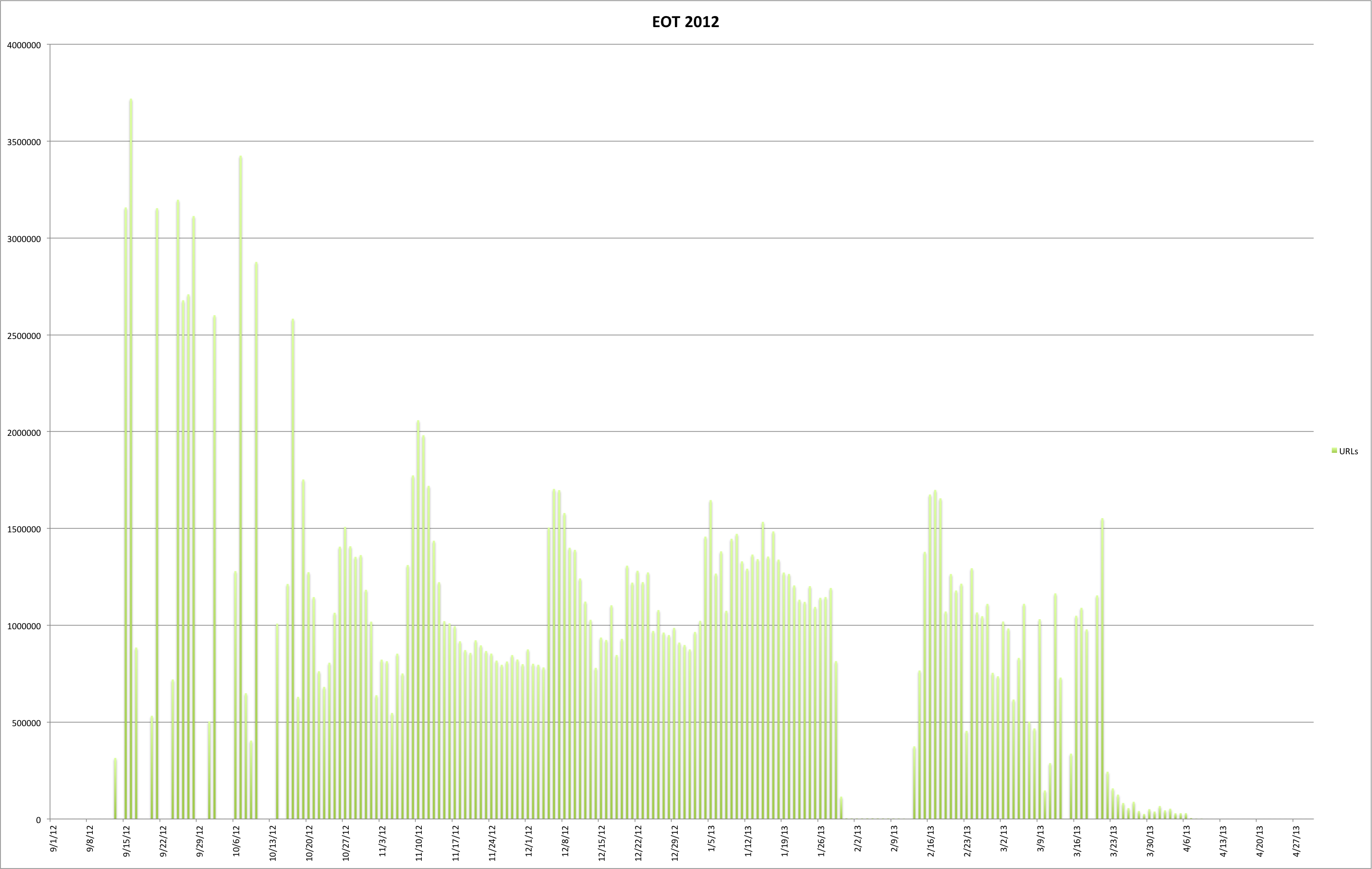
This post carries on in the analysis of the End of Term web archives for 2008 and 2012. Previous posts in this series discuss when content was harvested and what kind of content was harvested and included in the archives.
In this post we will look at where content came from, specifically the data held in the top level domains, domain names and sub-domain names.
Top Level Domains
The first thing to look at is the top level domains for all of the URLs in the CDX files.
In the EOT2008 archive there are a total of 241 unique TLDs. In the EOT2012 archive there are a total of 251 unique TLDs. This is a modest increase of 4.15% from EOT2008 to EOT2012.
The EOT2008 and EOT2012 archives share 225 TLDs between the two archives. There are 16 TLDs that are unique to the EOT2008 archive and 26 TLDs that are unique to the EOT2012 archive.
TLDs unique to EOT2008
| Unique to 2008 |
URLs from TLD |
| null |
18,772 |
| www |
583 |
| yu |
357 |
| labs |
20 |
| webteam |
16 |
| cg |
10 |
| security |
8 |
| ssl |
8 |
| b |
8 |
| css |
7 |
| web |
6 |
| dev |
4 |
| education |
4 |
| misc |
2 |
| secure |
2 |
| campaigns |
2 |
TLDs unique to EOT2012
| Unique to 2012 |
URLs from TLD |
| whois |
17,500 |
| io |
7,935 |
| pn |
987 |
| sy |
541 |
| lr |
478 |
| so |
418 |
| nr |
363 |
| tf |
291 |
| xxx |
258 |
| re |
186 |
| xn--p1ai |
171 |
| bi |
153 |
| dm |
120 |
| tel |
78 |
| ck |
65 |
| ax |
64 |
| sx |
54 |
| tg |
50 |
| ki |
48 |
| gg |
25 |
| kn |
25 |
| gp |
24 |
| pm |
20 |
| fk |
18 |
| cf |
7 |
| wf |
3 |
I believe that the “null” TLD from EOT2008 is an artifact of the crawling process and possibly represents rows in the CDX file that correspond to metadata records in the warc/arcs from 2008. I will have to do some digging to confirm.
Change in TLD
Next up we take a look at the 225 TLDs that are shared between the archives. First up are the fifteen most changed based on the increase or decrease in the number of URLs from that TLD
| TLD |
eot2008 |
eot2012 |
Change |
Absolute Change |
% change |
| com |
7,809,711 |
45,594,482 |
37,784,771 |
37,784,771 |
483.8% |
| gov |
137,829,050 |
109,141,353 |
-28,687,697 |
28,687,697 |
-20.8% |
| mil |
3,555,425 |
16,223,861 |
12,668,436 |
12,668,436 |
356.3% |
| net |
653,187 |
9,269,406 |
8,616,219 |
8,616,219 |
1319.1% |
| edu |
3,552,509 |
2,442,626 |
-1,109,883 |
1,109,883 |
-31.2% |
| int |
135,939 |
685,168 |
549,229 |
549,229 |
404.0% |
| uk |
70,262 |
594,020 |
523,758 |
523,758 |
745.4% |
| ly |
95 |
503,457 |
503,362 |
503,362 |
529854.7% |
| org |
5,108,645 |
5,588,750 |
480,105 |
480,105 |
9.4% |
| us |
840,516 |
474,156 |
-366,360 |
366,360 |
-43.6% |
| co |
2,839 |
211,131 |
208,292 |
208,292 |
7336.8% |
| be |
4,019 |
203,178 |
199,159 |
199,159 |
4955.4% |
| jp |
23,896 |
220,602 |
196,706 |
196,706 |
823.2% |
| me |
35 |
182,963 |
182,928 |
182,928 |
522651.4% |
| tv |
10,373 |
191,736 |
181,363 |
181,363 |
1748.4% |
Interesting is the change in the first two. There was an increase of over 37 million URLs (484%) for the com TDL between EOT2008 and EOT2012. There was also a decrease (-21%) or over 28 million URLs for the gov TLD. The mil TLD also increased by 356% between the EOT2008 and EOT2012 harvests with an increase of over 12 million URLs.
You can see that .ly and .me increased by some serious percentage, 529,855% and 522,651% respectively.
Taking a look at just the percent of change, here are the five most changed based on that percentage
| TLD |
eot2008 |
eot2012 |
Change |
Absolute Change |
% change |
| ly |
95 |
503,457 |
503,362 |
503,362 |
529854.7% |
| me |
35 |
182,963 |
182,928 |
182,928 |
522651.4% |
| gl |
129 |
49,733 |
49,604 |
49,604 |
38452.7% |
| gd |
9 |
3,273 |
3,264 |
3,264 |
36266.7% |
| cat |
43 |
11,703 |
11,660 |
11,660 |
27116.3% |
I have a feeling that at the majority of the ly, me, gl, and gd TLD content came in as redirect URLs from link shortening services.
Domain Names
There are 87,889 unique domain names in the EOT2008 archive, this increases dramatically in the EOT2012 archive to 186,214 which is an increase of 118% in the number of domain names.
There are 30,066 domain names that are shared between the two archives. There are 57,823 domain names that are unique to the EOT2008 archive and 156.148 domain names that are unique to the EOT2012 archive.
Here is a table showing thirty of the domains that were only present in the EOT2008 archive ordered by the number of URLs from that domain.
| TLD |
Count |
| geodata.gov |
812,524 |
| nifl.gov |
504,910 |
| stat-usa.gov |
398,961 |
| tradestatsexpress.gov |
243,729 |
| arnet.gov |
174,057 |
| acqnet.gov |
171,493 |
| dccourts.gov |
161,289 |
| meish.org |
147,261 |
| web-services.gov |
137,202 |
| metrokc.gov |
132,210 |
| sdi.gov |
91,887 |
| davie-fl.gov |
88,123 |
| belmont.gov |
87,332 |
| aftac.gov |
84,507 |
| careervoyages.gov |
57,192 |
| women-21.gov |
56,255 |
| egrpra.gov |
54,775 |
| 4women.gov |
45,684 |
| 4woman.gov |
42,192 |
| nypa.gov |
36,099 |
| secure-banking.com |
33,059 |
| nhmfl.gov |
27,569 |
| darpa.gov |
21,454 |
| usafreedomcorps.gov |
18,001 |
| peacecore.gov |
17,744 |
| californiadesert.gov |
15,172 |
| federaljudgesassoc.org |
15,126 |
| arpa.gov |
15,093 |
| transportationfortomorrow.org |
14,926 |
| okgeosurvey1.gov |
14,595 |
Here is the same kind of table but this time for the EOT2012 dataset.
| TLD |
Count |
| militaryonesource.mil |
859,843 |
| yfrog.com |
682,664 |
| staticflickr.com |
640,606 |
| akamaihd.net |
384,769 |
| 4sqi.net |
350,707 |
| foursquare.com |
340,492 |
| adf.ly |
334,767 |
| pinterest.com |
244,293 |
| consumerfinance.gov |
237,361 |
| nrd.gov |
194,215 |
| wh.gov |
179,233 |
| t.co |
175,033 |
| youtu.be |
172,301 |
| sndcdn.com |
161,039 |
| pnnl.gov |
132,994 |
| eia.gov |
112,034 |
| transparency.gov |
109,039 |
| nationalguard.mil |
108,854 |
| acus.gov |
93,810 |
| nrsc.org |
85,925 |
| mzstatic.com |
84,202 |
| 404.gov |
82,409 |
| savingsbondwizard.gov |
76,867 |
| treasuryhunt.gov |
76,394 |
| mynextmove.org |
75,927 |
| fedshirevets.gov |
75,529 |
| onrr.gov |
75,484 |
| veterans.gov |
75,350 |
| broadbandmap.gov |
72,889 |
| ntm-a.com |
71,126 |
Those are pretty long tables but I think they start to point at some interesting things from this analysis. The domains that were present and harvested in 2008 and that weren’t harvested in 2012. In looking at the list, some of them (metrokc.gov, davie-fl.gov, okgeosurvey1.gov) were most likely out of scope for “Federal Web” but got captured because of the gov TLD.
In the EOT2012 list you start to see artifacts from an increase in attention to social media site capture for the EOT2012 project. Sites like yfrog.com, staticflickr.com, adf.ly, t.co, youtu.be, foursquare.com, pintrest.com probably came from that increased attention.
Here is a list of the twenty most changed domains from EOT2008 to EOT2012. This number is based on the absolute change in the number of URLs captured for each of the archives.
| Domain |
EOT2008 |
EOT2012 |
Change |
Abolute Change |
% Change |
| house.gov |
13,694,187 |
35,894,356 |
22,200,169 |
22,200,169 |
162% |
| facebook.com |
11,895 |
7,503,640 |
7,491,745 |
7,491,745 |
62,982% |
| dvidshub.net |
1,097 |
5,612,410 |
5,611,313 |
5,611,313 |
511,514% |
| senate.gov |
5,043,974 |
9,924,917 |
4,880,943 |
4,880,943 |
97% |
| gpo.gov |
8,705,511 |
3,888,645 |
-4,816,866 |
4,816,866 |
-55% |
| nih.gov |
5,276,262 |
1,267,764 |
-4,008,498 |
4,008,498 |
-76% |
| nasa.gov |
6,693,542 |
3,063,382 |
-3,630,160 |
3,630,160 |
-54% |
| navy.mil |
94,081 |
3,611,722 |
3,517,641 |
3,517,641 |
3,739% |
| usgs.gov |
4,896,493 |
1,690,295 |
-3,206,198 |
3,206,198 |
-65% |
| loc.gov |
5,059,848 |
7,587,179 |
2,527,331 |
2,527,331 |
50% |
| flickr.com |
157,155 |
2,286,890 |
2,129,735 |
2,129,735 |
1,355% |
| youtube.com |
346,272 |
2,369,108 |
2,022,836 |
2,022,836 |
584% |
| hhs.gov |
2,361,866 |
366,024 |
-1,995,842 |
1,995,842 |
-85% |
| osd.mil |
180,046 |
2,111,791 |
1,931,745 |
1,931,745 |
1,073% |
| af.mil |
230,920 |
2,067,812 |
1,836,892 |
1,836,892 |
795% |
| ed.gov |
2,334,548 |
510,413 |
-1,824,135 |
1,824,135 |
-78% |
| granicus.com |
782 |
1,785,724 |
1,784,942 |
1,784,942 |
228,253% |
| lanl.gov |
2,081,275 |
309,007 |
-1,772,268 |
1,772,268 |
-85% |
| usda.gov |
2,892,923 |
1,324,049 |
-1,568,874 |
1,568,874 |
-54% |
| googleusercontent.com |
2 |
1,560,457 |
1,560,455 |
1,560,455 |
78,022,750% |
You see big increases in facebook.com (+62,982%), flickr.com (+1,355%), youtube.com (584%) and googleusercontent.com (78,022,750%) in content from EOT2008 to EOT2012.
Other increases that are notable include dvidshub.net which is the domain for a site called Defense Video & Imagery Distribution System that increased by 511,514%, navy.mil (3,739%), osd.mil (1,073%), af.mil (795%). I like to think this speaks to a desired increase in attention to .mil content in the EOT2012 project.
Another domain that stands out to me is granicus.com which I was unaware of but after a little looking turns out to be one of the big cloud service providers for the federal government (or at least it was according to the EOT2012 dataset).
.gov and .mil subdomains
The last piece I wanted to look at related to domain names was to see what sort of changes there were in the gov and mil portions of the EOT2008 and EOT2012 crawls. This time I wanted to look at the subdomains.
I filtered my dataset a bit so that I was only looking at the .mil and .gov content.
In the EOT2008 archive there were a total of 16,072 unique subdomains and in EOT2012 there were 22,477 subdomains. This is an increase of 40% between the two archive projects.
The EOT2008 has 5,371 subdomains unique to its holdings and EOT2012 has 11,776 unique subdomains.
Subdomains that had the most content (based on URLs downloaded) and which are only present in EOT2008 are presented below. (Limited to the top 30)
| EOT2008 Subdomain |
Count |
| gos2.geodata.gov |
809,442 |
| boucher.house.gov |
772,759 |
| kendrickmeek.house.gov |
685,368 |
| citizensbriefingbook.change.gov |
446,632 |
| stat-usa.gov |
305,936 |
| nifl.gov |
285,833 |
| scidac-new.ca.sandia.gov |
247,451 |
| tradestatsexpress.gov |
243,729 |
| hpcf.nersc.gov |
221,626 |
| gopher.info.usaid.gov |
219,051 |
| novel.nifl.gov |
218,962 |
| dli2.nsf.gov |
206,932 |
| contractorsupport.acf.hhs.gov |
188,841 |
| pnwin.nbii.gov |
188,591 |
| faq.acf.hhs.gov |
184,212 |
| ccdf.acf.hhs.gov |
182,606 |
| arnet.gov |
174,018 |
| regulations.acf.hhs.gov |
171,762 |
| acqnet.gov |
171,493 |
| dccourts.gov |
161,289 |
| employers.acf.hhs.gov |
139,141 |
| search.info.usaid.gov |
137,816 |
| web-services.gov |
137,202 |
| earth2.epa.gov |
136,441 |
| cjtf7.army.mil |
134,507 |
| ncweb-north.wr.usgs.gov |
134,486 |
| opre.acf.hhs.gov |
133,689 |
| childsupportenforcement.acf.hhs.gov |
132,023 |
| modis-250m.nascom.nasa.gov |
128,810 |
| casd.uscourts.gov |
124,146 |
Here is the same sort of data for the EOT2012 dataset
| EOT2012 Subdomain |
Count |
| militaryonesource.mil |
698,035 |
| uscodebeta.house.gov |
387,080 |
| democrats.foreignaffairs.house.gov |
312,270 |
| gulflink.fhpr.osd.mil |
262,246 |
| coons.senate.gov |
257,721 |
| democrats.energycommerce.house.gov |
243,341 |
| consumerfinance.gov |
225,815 |
| dcmo.defense.gov |
217,255 |
| nrd.gov |
187,267 |
| wh.gov |
179,103 |
| usaxs.xray.aps.anl.gov |
178,298 |
| democrats.budget.house.gov |
175,109 |
| democrats.edworkforce.house.gov |
162,077 |
| apps.militaryonesource.mil |
157,144 |
| naturalresources.house.gov |
155,918 |
| purl.fdlp.gov |
154,718 |
| media.dma.mil |
137,581 |
| algreen.house.gov |
131,388 |
| democrats.transportation.house.gov |
129,345 |
| democrats.naturalresources.house.gov |
124,808 |
| hanabusa.house.gov |
123,794 |
| pitts.house.gov |
122,402 |
| visclosky.house.gov |
122,223 |
| garamendi.house.gov |
114,221 |
| vault.fbi.gov |
113,873 |
| green.house.gov |
113,040 |
| sewell.house.gov |
112,973 |
| levin.house.gov |
111,971 |
| eia.gov |
111,889 |
| hahn.house.gov |
111,024 |
This last table is a little long, but I found the data pretty interesting to look at. The table below shows the biggest change for domains and subdomains that were shared between the EOT2008 and EOT2012 archives. I’ve included the top forty entries for that list.
| Subdomain/Domain |
EOT2008 |
EOT2012 |
Change |
Absolute Change |
% Change |
| listserv.access.gpo.gov |
2,217,565 |
7,487 |
-2,210,078 |
2,210,078 |
-100% |
| carter.house.gov |
1,898,462 |
29,680 |
-1,868,782 |
1,868,782 |
-98% |
| catalog.gpo.gov |
1,868,504 |
34,040 |
-1,834,464 |
1,834,464 |
-98% |
| loc.gov |
63,534 |
1,875,264 |
1,811,730 |
1,811,730 |
2,852% |
| gpo.gov |
52,427 |
1,796,925 |
1,744,498 |
1,744,498 |
3,327% |
| bensguide.gpo.gov |
90,280 |
1,790,017 |
1,699,737 |
1,699,737 |
1,883% |
| edocket.access.gpo.gov |
1,644,578 |
7,822 |
-1,636,756 |
1,636,756 |
-100% |
| nws.noaa.gov |
103,367 |
1,676,264 |
1,572,897 |
1,572,897 |
1,522% |
| navair.navy.mil |
220 |
1,556,320 |
1,556,100 |
1,556,100 |
707,318% |
| congress.gov |
1,525,467 |
356 |
-1,525,111 |
1,525,111 |
-100% |
| cha.house.gov |
1,366,520 |
109,192 |
-1,257,328 |
1,257,328 |
-92% |
| usbg.gov |
1,026,360 |
6,724 |
-1,019,636 |
1,019,636 |
-99% |
| dol.gov |
1,052,335 |
41,909 |
-1,010,426 |
1,010,426 |
-96% |
| resourcescommittee.house.gov |
1,008,655 |
335 |
-1,008,320 |
1,008,320 |
-100% |
| calvert.house.gov |
20,530 |
1,014,416 |
993,886 |
993,886 |
4,841% |
| fdlp.gov |
989,415 |
1,554 |
-987,861 |
987,861 |
-100% |
| lcweb2.loc.gov |
466,623 |
1,451,708 |
985,085 |
985,085 |
211% |
| cramer.house.gov |
1,011,872 |
60,879 |
-950,993 |
950,993 |
-94% |
| ed.gov |
1,141,069 |
241,165 |
-899,904 |
899,904 |
-79% |
| vaccines.mil |
5,638 |
856,113 |
850,475 |
850,475 |
15,085% |
| clinicaltrials.gov |
919,362 |
193,158 |
-726,204 |
726,204 |
-79% |
| army.mil |
4,831 |
725,934 |
721,103 |
721,103 |
14,927% |
| boehner.house.gov |
7,472 |
695,625 |
688,153 |
688,153 |
9,210% |
| nces.ed.gov |
702,644 |
31,922 |
-670,722 |
670,722 |
-95% |
| prc.gov |
739,849 |
75,682 |
-664,167 |
664,167 |
-90% |
| navy.mil |
1,481 |
654,254 |
652,773 |
652,773 |
44,077% |
| house.gov |
818,095 |
172,066 |
-646,029 |
646,029 |
-79% |
| fueleconomy.gov |
675,522 |
79,943 |
-595,579 |
595,579 |
-88% |
| fema.gov |
636,005 |
53,321 |
-582,684 |
582,684 |
-92% |
| frwebgate.access.gpo.gov |
621,361 |
55,097 |
-566,264 |
566,264 |
-91% |
| siadapp.dmdc.osd.mil |
43 |
559,076 |
559,033 |
559,033 |
1,300,077% |
| fdsys.gpo.gov |
548,618 |
28 |
-548,590 |
548,590 |
-100% |
| tiger.census.gov |
549,046 |
750 |
-548,296 |
548,296 |
-100% |
| rs6.loc.gov |
550,489 |
6,695 |
-543,794 |
543,794 |
-99% |
| bennelson.senate.gov |
16,203 |
553,698 |
537,495 |
537,495 |
3,317% |
| crapo.senate.gov |
28,569 |
540,928 |
512,359 |
512,359 |
1,793% |
| eia.doe.gov |
508,675 |
1,629 |
-507,046 |
507,046 |
-100% |
| epa.gov |
623,457 |
117,794 |
-505,663 |
505,663 |
-81% |
| defenselink.mil |
502,006 |
1,866 |
-500,140 |
500,140 |
-100% |
| access.gpo.gov |
472,373 |
3,110 |
-469,263 |
469,263 |
-99% |
I find this table interesting for a number of reasons. First you see quite a bit more decline that I have seen in my other tables like this. In fact 26 of the 40 subdomains/domains (54%) on this list decreased from EOT2008 to EOT2012.
In looking at the list as well I can see some of the sites that I can see the transition of some of the sites within GPO, for example access.gpo.gov going down 90% in captured content, fdsys.gpo.gov going down by 94%, bensguide.gpo.gov increasing by 1,883%.
Wrapping Up
I like to think that it helps to justify some of the work that the partners of the End of Term project are committing to the project when you see that there are large numbers of domains and subdomains that existed in 2008 but that weren’t crawled again in 2012 (and we can only assume they weren’t around in 2012).
There are a few more things I want to look at in this work so stay tuned.
If you have questions or comments about this post, please let me know via Twitter.