This is the last post in a series of posts related to the Description field found in the Digital Public Library of America. I’ve been working with a collection of 11,654,800 metadata records for which I’ve created a dataset of 17,884,946 description fields.
This past Christmas I received a copy of Thing Explainer by Randall Munroe, if you aren’t familiar with this book, Randall uses only the most used ten hundred words (thousand isn’t one of them) to describe very complicated concepts and technologies.
After seeing this book I started to wonder how much of the metadata we create for our digital objects use just the 1,000 most frequent words. Often frequently used words, as well as less complex words (words with fewer syllables) are used in the calculation of the reading level of various texts so that also got me thinking about the reading level required to understand some of our metadata records.
Along that train of thought, one of the things that we hear from aggregations of cultural heritage materials is that K-12 users are a target audience we have and that many of the resources we digitize are with them in mind. With that being said, how often do we take them into account when we create our descriptive metadata?
When I was indexing the description fields I calculated three metrics related to this.
- What percentage of the tokens are in the 1,000 most frequently used English words
- What percentage of the tokens are in the 5,000 most frequently used English words
- What percentage of the tokens are words in a standard English dictionary.
From there I was curious about how the different providers compared to each other.
Average for 1,000, 5,000 and English Dictionary
1,000 most Frequent English Words
The first thing we will look at is the average of amount of a description composed of words from the list of the 1,000 most frequently used English words.
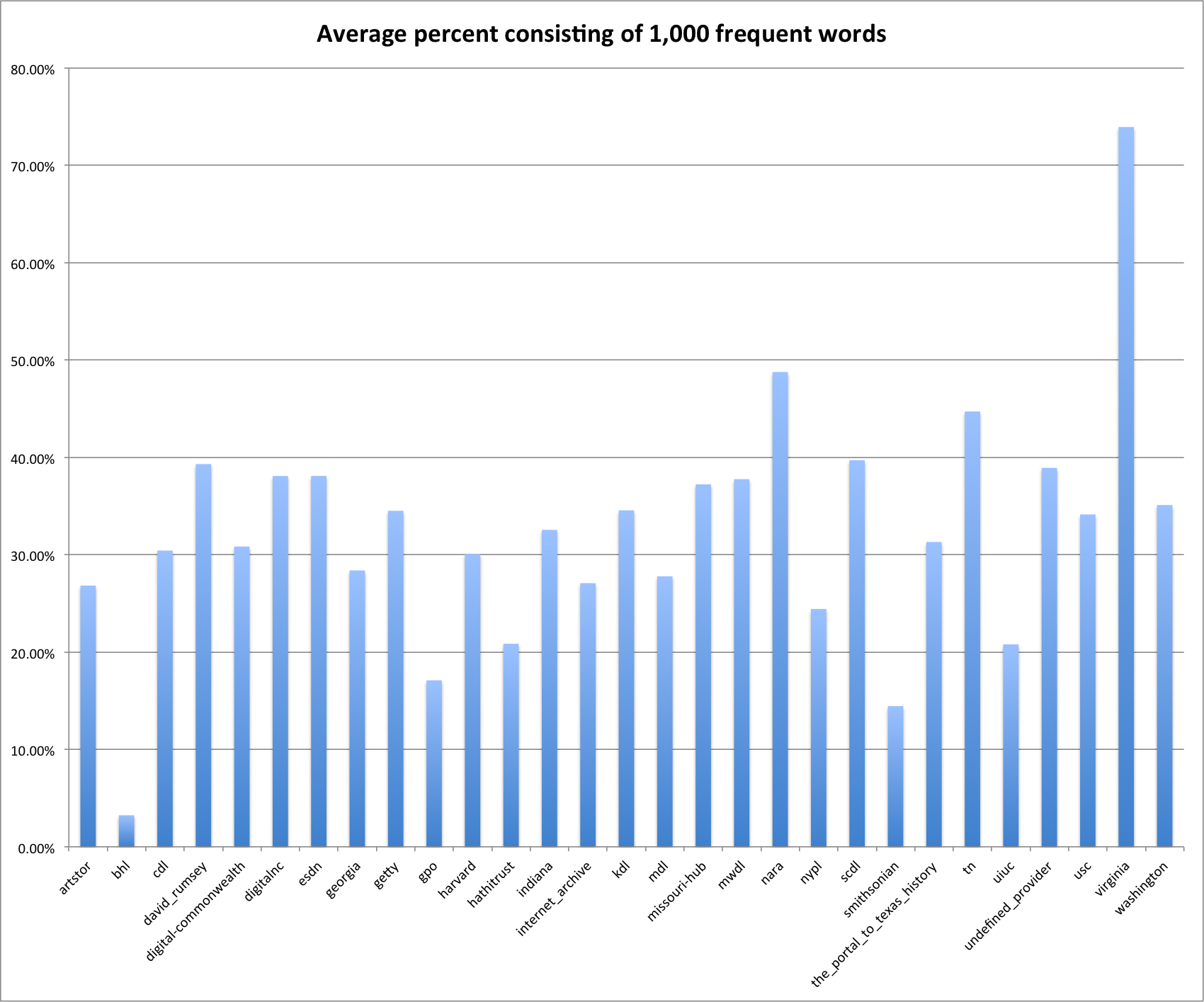
Average percentage of description consisting of 1000 most frequent English words.
For me the providers/hubs that I notice are of course bhl that has very little usage of the 1,000 word vocabulary. This is followed by smithsonian, gpo, hathitrust and uiuc. On the other end of the scale is virginia that has an average of 70%.
5,000 most Frequent English Words
Next up is the average percentage of the descriptions that consist of words from the 5,000 most frequently used English words.
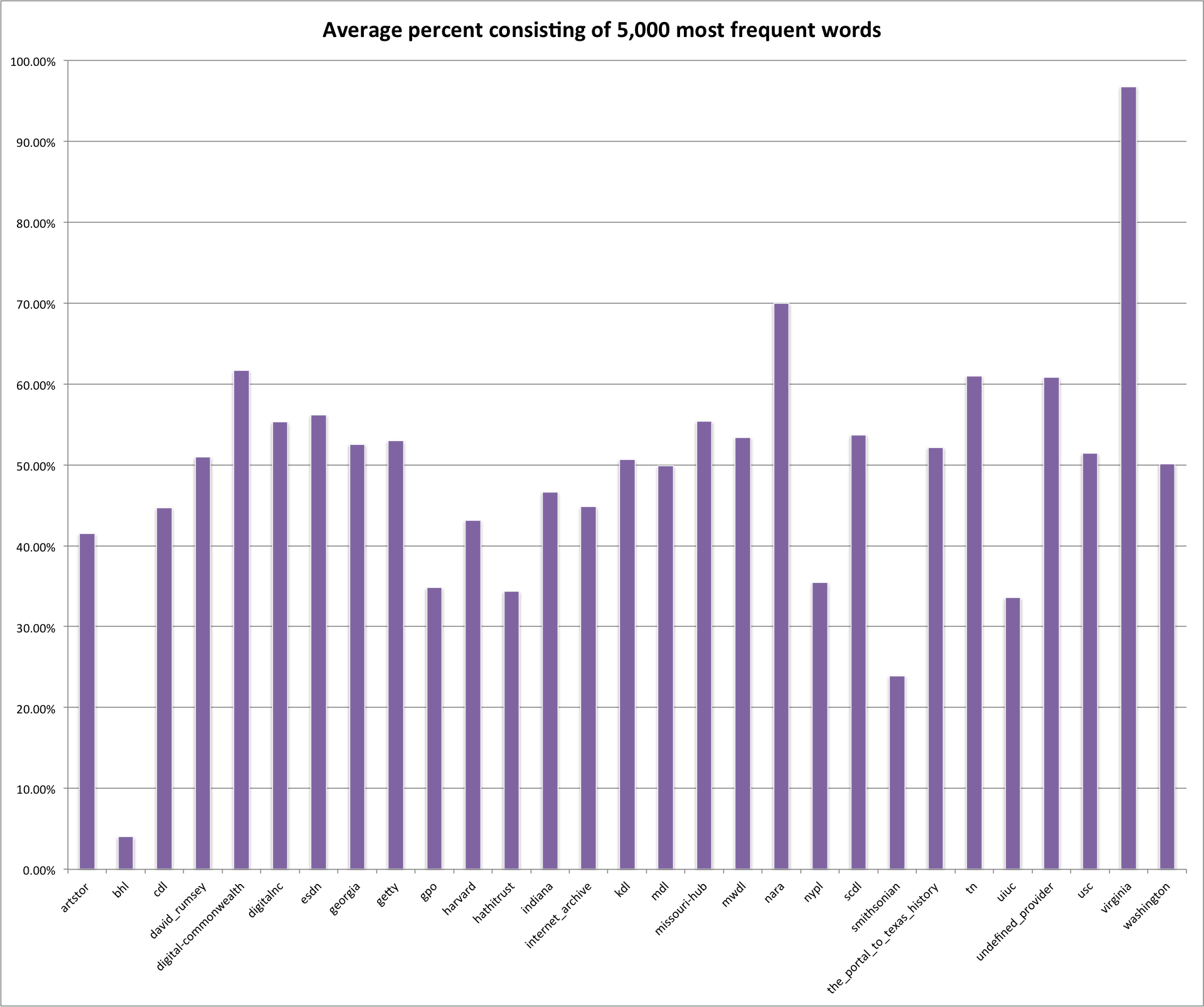
Average percentage of description consisting of 5000 most frequent English words.
This graph ends up looking very much like the 1,000 words graph, just a bit higher percentage wise. This is due to the fact of course that the 5,000 word list includes the 1,000 word list. You do see a few changes in the ordering though, for example gpo switches places with hathitrust in this graph over the 1,000 words graph above.
English Dictionary Words
Next is the average percentage of descriptions that consist of words from a standard English dictionary. Again this includes the 1,000 and 5,000 words in that dictionary so it will be even higher.
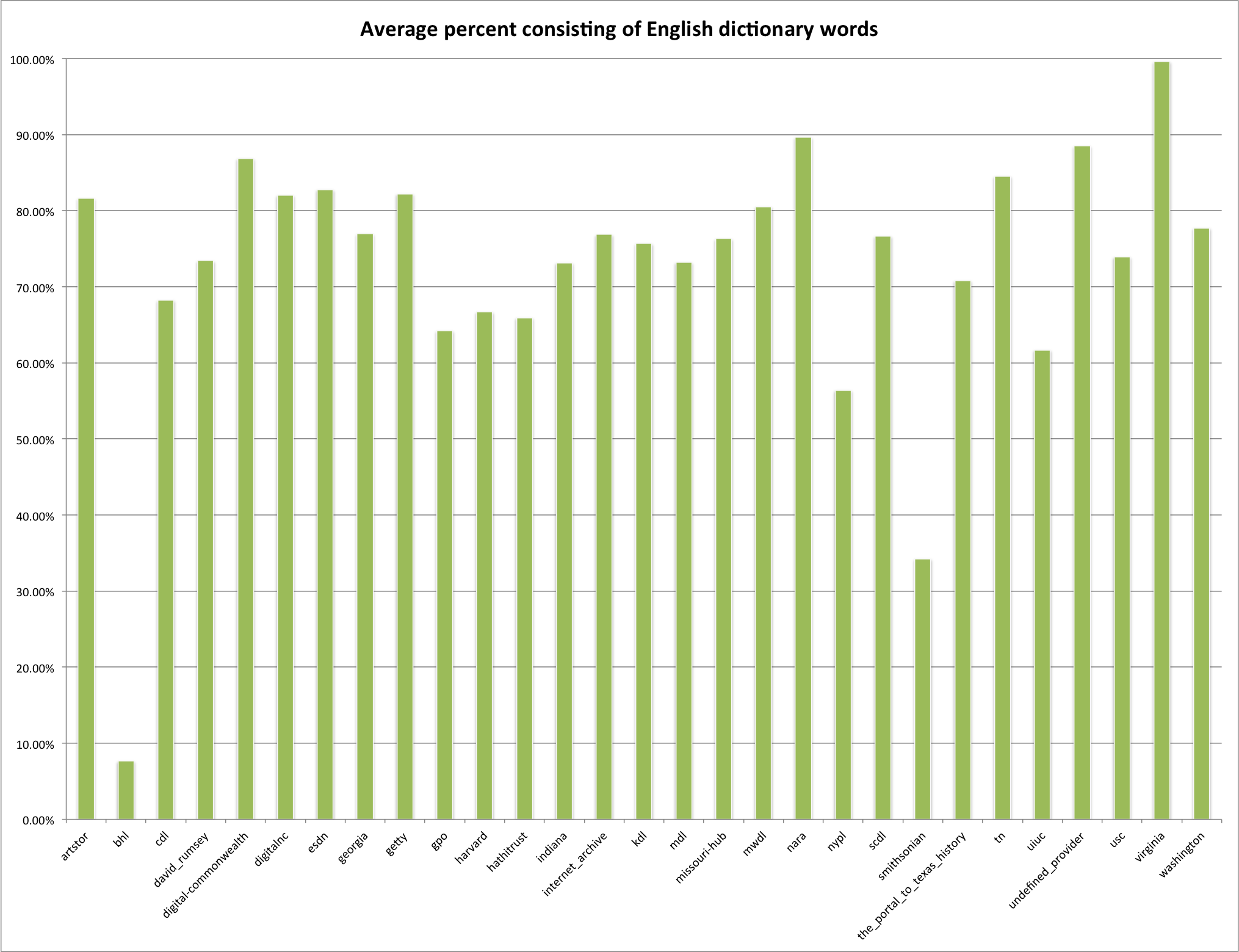
Average percentage of description consisting of English dictionary words.
You see that the virginia hub has almost 100% or their descriptions consisting of English dictionary words. The hubs that are the lowest in their use of English words for descriptions are bhl, smithsonian, and nypl.
The graph below has 1,000, 5,000, and English Dictionary words grouped together for each provider/hub so you can see at a glance how they stack up.
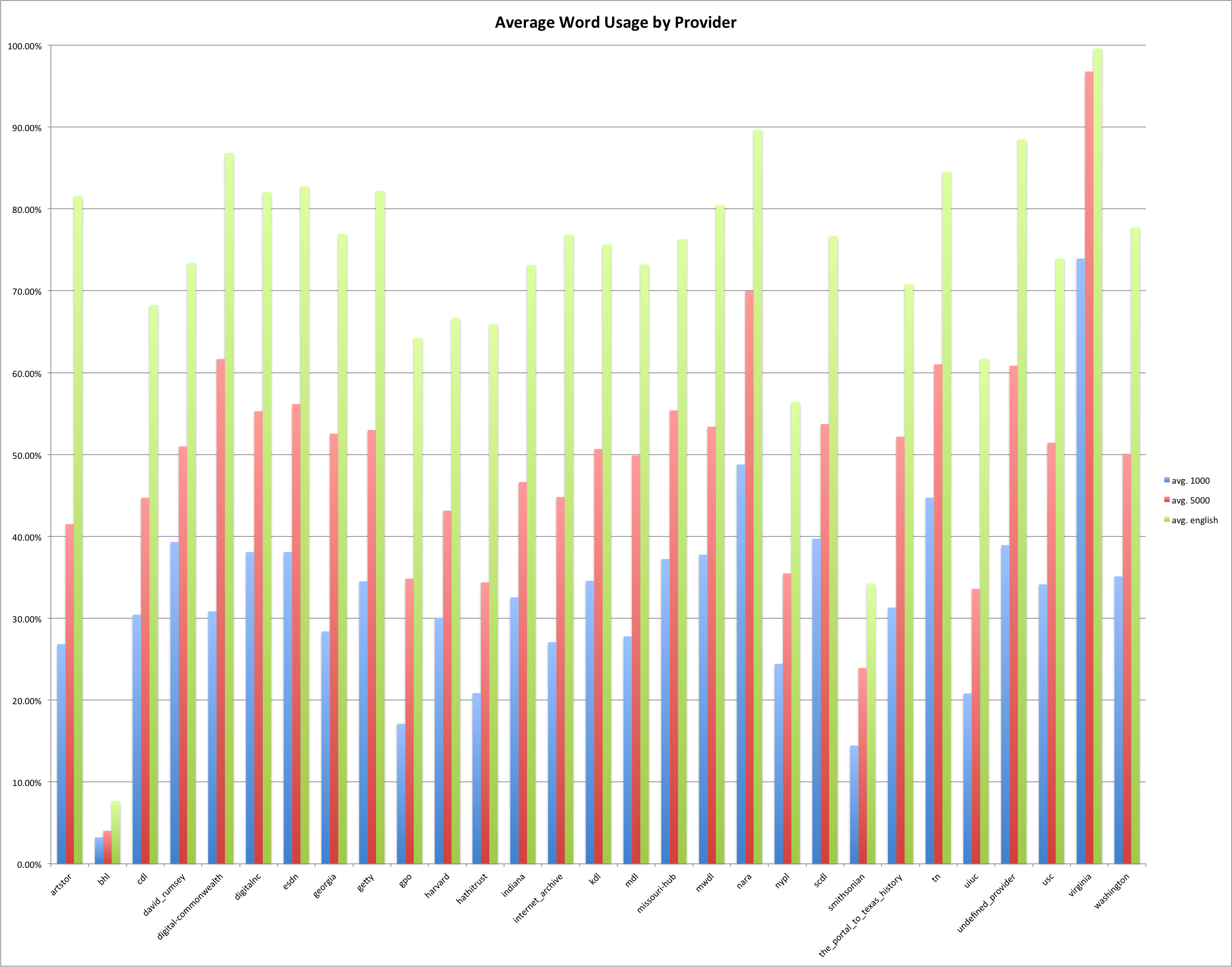
1,000, 5,000 most frequent English words and English dictionary words by Provider
Stacked Percent 1,000, 5,000, English Dictionary
Next we will look at the percentages per provider/hub if we group the percentage utilization into 25% buckets. This gives a more granular view of the data than just the averages presented above.
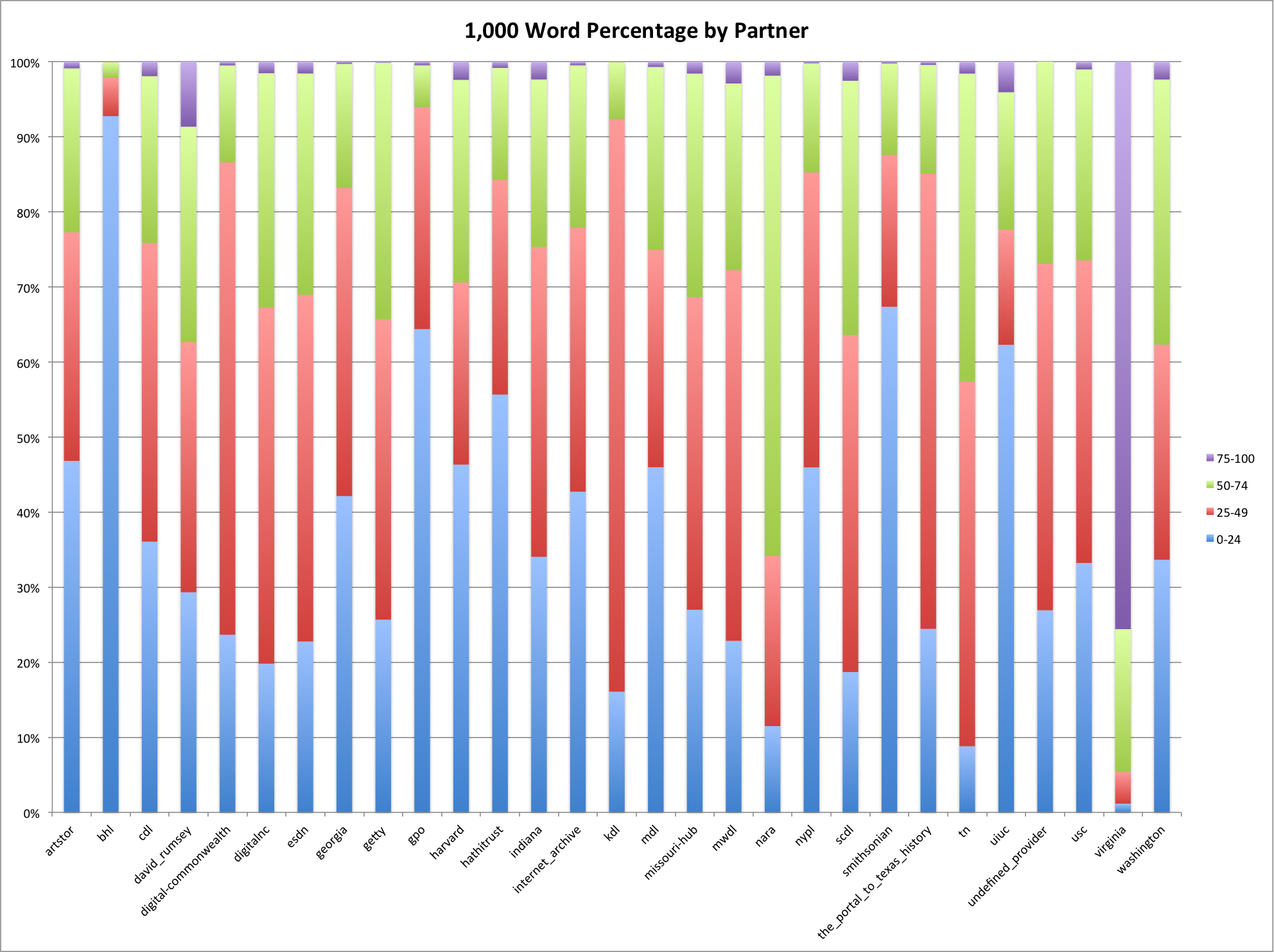
Percentage of descriptions by provider that use 1,000 most frequent English words.
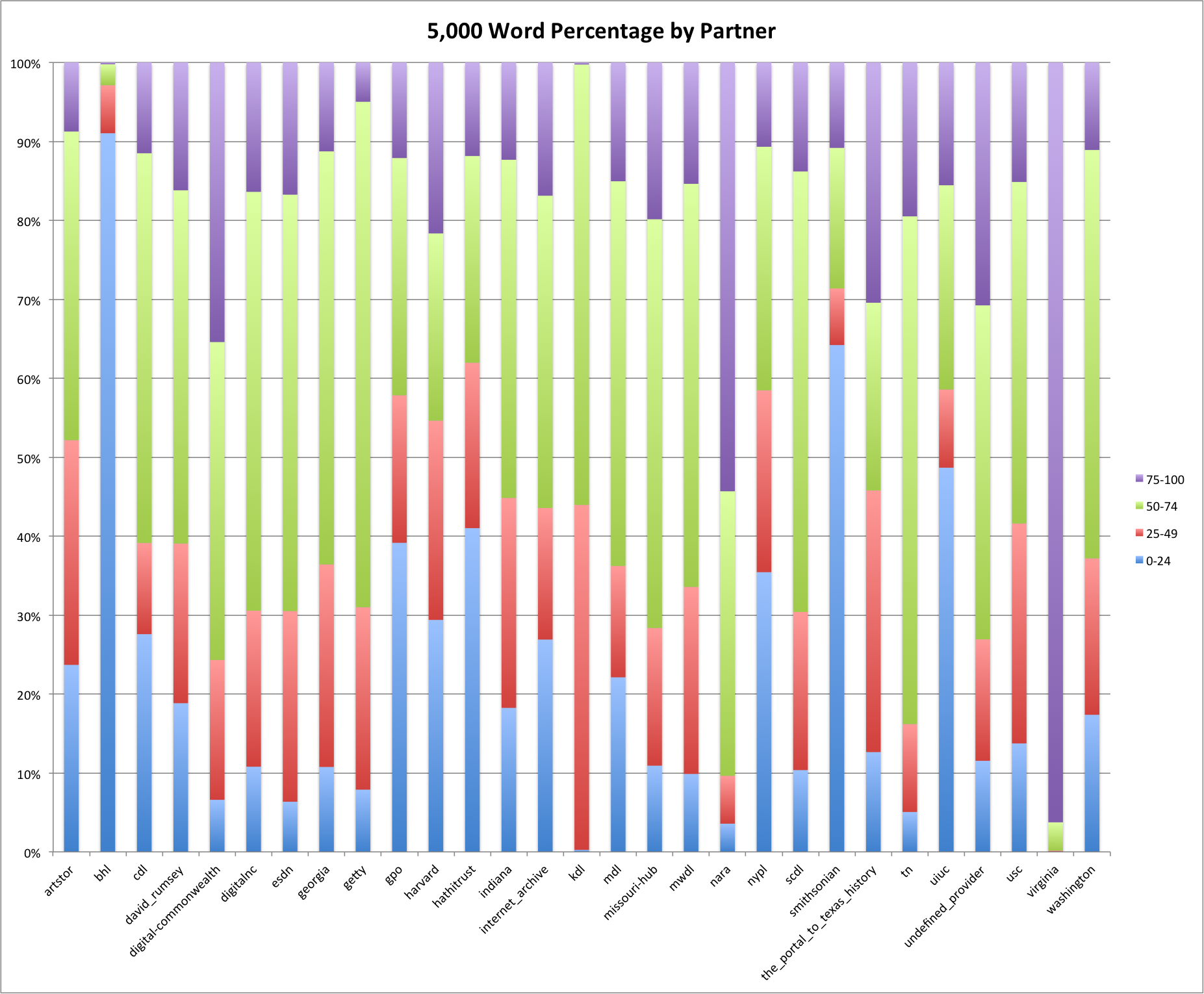
Percentage of descriptions by provider that use 5,000 most frequent English words.

Percentage of descriptions by provider that use English dictionary words.
Closing
I don’t think it is that much of a stretch to draw parallels between the language used in our descriptions and the intended audience of our metadata records. How often are we writing metadata records for ourselves instead of our users? A great example that comes to mind is “verso” or “recto” that we use often for “front” and “back” of items. In the dataset I’ve been using there are 56,640 descriptions with the term “verso” and 5,938 with the term “recto”.
I think we should be taking into account our various audiences when we are creating metadata records. I know this sounds like a very obvious suggestion but I don’t think we really do that when we are creating our descriptive metadata records. Is there a target reading level for metadata records? Should there be?
Looking at the description fields in the DPLA dataset has been interesting. The kind of analysis that I’ve done so far can be seen as kind of a distant reading of these fields. Big round numbers that are pretty squishy and only show the general shape of the field. To dive in and do a close reading of the metadata records is probably needed to better understand what is going on in these records.
Based on experience of mapping descriptive metadata into the Dublin Core metadata fields, I have a feeling that the description field is generally a dumping ground for information that many of us might not consider “description”. I sometimes wonder if it would do our users a greater service by adding a true “note” field to our metadata models so that we have a proper location to dump “notes and other stuff” instead of muddying up a field that should have an obvious purpose.
That’s about it for this work with descriptions, or at least it is until I find some interest in really diving deeper into the data.
If you have questions or comments about this post, please let me know via Twitter.