Metadata quality and assessment is a concept that has been around for decades in the library community. Recently it has been getting more interest as new aggregations of metadata become available in open and freely reusable ways such as the Digital Public Library of America (DPLA) and Europeana. Both of these groups make available their metadata so that others can remix and reuse the data in new ways.
I’ve had an interest in analyzing the metadata in the DPLA for a while and have spent some time working on the subject fields. This post will continue along those lines in trying to figure out what some of the metrics that we can calculate with the DPLA dataset that we can use to define “quality”. Ideally we will be able to turn these assessments and notions of quality into concrete recommendations for how to improve metadata records in the originating repositories.
This post will focus on normalization of subject strings, and how those normalizations might be useful as a way of assessing quality of a set of records.
One of the the powerful features of OpenRefine is the ability to cluster a set or data and combine these clusters into a single entry. Often times this will significantly reduce the number of values that occur in a dataset in a quick and easy manner.
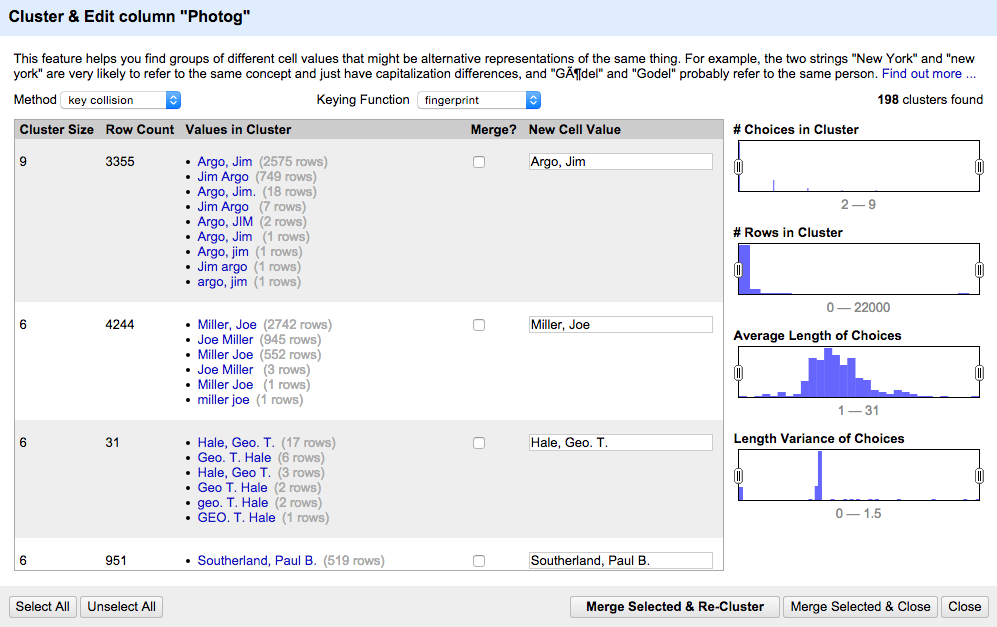
OpenRefine Cluster and Edit Screen Capture
OpenRefine has a number different algorithms that can be used for this work that are documented in their Clustering in Depth documentation. Depending on ones data one approach may perform better than others for this kind of clustering.
Normalization
Case normalization is probably the easiest to kind of normalization to understand. If you have two strings, say “Mark” and “marK” if you converted each of the strings to lowercase you would end up with a single value of “mark”. Many more complicated normalizations assume this as a start because it reduces the number of subjects without drastically transforming the original string values.
Case folding is another kind of transformation that is fairly common in the world of libraries. This is the process of taking a string like “José” and converting it to “Jose”. While this can introduce issues if a string is meant to have a diacritic and that diacritic makes the word or phrase different than the one without the diacritic, often times it can help to normalize inconsistently notated versions of the same string.
In addition to case folding and lower casing, libraries have been normalizing data for a long time, there have been efforts in the past to formalize algorithms for the normalization of subject strings for use in matching these strings. Often referred to as NACO normalizations rules, they are Authority File Comparison Rules. I’ve always found this work to be intriguing and have a preference for the work and simplified algorithm that was developed at OCLC in their NACO Normalization Service. In fact we’ve taken the sample Python implementation there and created a stand-alone repository and project called pynaco on GitHub for the code so that we could add tests and then work to port it Python 3 in the near future.
Another common type of normalization that is performed on strings in library land is stemming. This is often done within search applications so that if you search one of the phrases run, runs, running you would get documents that contain each of these.
What I’ve been playing around with is if we could use the reduction in unique terms for a field in a metadata repository as an indicator of quality.
Here is an example.
If we have the following sets of subjects:
Musical Instruments Musical Instruments. Musical instrument Musical instruments Musical instruments, Musical instruments.
If you applied the simplified NACO normalization from pynaco you would end up with the following strings:
musical instruments musical instruments musical instrument musical instruments musical instruments musical instruments
If you then applied the porter stemming algorithm to the new set of subjects you would end up with the following:
music instrument music instrument music instrument music instrument music instrument music instrument
So in effect you have normalized the original set of six unique subjects down to one unique subject strings with a NACO transformation followed by a normalization with the Porter Stemming algorithm.
Experiment
In some past posts here, here, here, and here, I discussed some of the aspects of the subject fields present in Digital Public Library of America dataset. I dusted that dataset off and extracted all of the subjects from the dataset so that I could work with them by themselves.
I ended up with a set of text files that were 23,858,236 lines long that held the item identifier and a subject value for each subject of each item in the DPLA dataset. Here is a short snippet of what that looks like.
d8f192def7107b4975cf15e422dc7cf1 Hoggson Brothers d8f192def7107b4975cf15e422dc7cf1 Bank buildings--United States d8f192def7107b4975cf15e422dc7cf1 Vaults (Strong rooms) 4aea3f45d6533dc8405a4ef2ff23e324 Public works--Illinois--Chicago 4aea3f45d6533dc8405a4ef2ff23e324 City planning--Illinois--Chicago 4aea3f45d6533dc8405a4ef2ff23e324 Art, Municipal--Illinois--Chicago 63f068904de7d669ad34edb885925931 Building laws--New York (State)--New York 63f068904de7d669ad34edb885925931 Tenement houses--New York (State)--New York 1f9a312ffe872f8419619478cc1f0401 Benedictine nuns--France--Beauvais
Once I have the data in this format I could experiment with different normalizations to see what kind of effect they had on the dataset.
Total vs Unique
The first thing I did was to make the 23,858,236 long text file only contain unique values. I do this with the tried and true method of using unix sort and uniq.
sort subjects_all.txt | uniq > subjects_uniq.txt
After about eight minutes of waiting I ended up with a new text file subjects_uniq.txt that contains the unique subject strings in the dataset. There are a total of 1,871,882 unique subject strings in this file.
Case folding
Using a Python script to perform case folding on each of the unique subjects I’m able to see is that causes a reduction in the number of unique subjects.
I started out with 1,871,882 unique subjects and after case folding ended up with 1,867,129 unique subjects. That is a difference of 4,753 or a 0.25% reduction in the number of unique subjects. So nothing huge.
Lowercase
The next normalization tested was lowercasing of the values. I chose to do this on the set of subjects that were already case folded to take advantage of the previous reduction in the dataset.
By converting the subject strings to lowercase I reduced the number of unique case folded subjects from 1,867,129 to 1,849,682 which is a reduction of 22,200 or a 1.2% reduction from the original 1,871,882 unique subjects.
NACO Normalization
Next we look at the simple NACO normalization from pynaco. I applied this to the unique lower cased subjects from the previous step.
With the NACO normalization, I end up with 1,826,523 unique subject strings from the 1,849,682 that I started with from the lowercased subjects. This is a difference of 45,359 or a 2.4% reduction from the original 1,871,882 unique subjects.
Porter stemming
Moving along, I looked at for this work was applying the Porter Stemming algorithm to the output of the NACO normalized subjects from the previous step. I used the Porter implementation from the Natural Language Tool Kit (NLTK) for Python.
With the Portal stemmer applied, I ended up with 1,801,114 unique subject strings from the 1,826,523 that I started with from the NACO normalized subjects. This is a difference of 70,768 or a 3.8% reduction from the original 1,871,882 unique subjects.
Fingerprint
Finally I used a python porting of the fingerprint algorithm that OpenRefine uses for its clustering feature. This will help to normalize strings like “phillips mark” and “mark phillips” into a single value of “mark phillips”. I used the output of the previous Porter stemming step as the input for this normalization.
With the fingerprint algorithm applied, I ended up with 1,766,489 unique fingerprint normalized subject strings. This is a difference of 105,393 or a 5.6% reduction from the original 1,871,882 unique subjects.
Overview
| Reduction | Occurrences | Percent Reduction | |
| Unique | 0 | 1,871,882 | 0% |
| Case Folded | 4,753 | 1,867,129 | 0.3% |
| Lowercase | 22,200 | 1,849,682 | 1.2% |
| NACO | 45,359 | 1,826,523 | 2.4% |
| Porter | 70,768 | 1,801,114 | 3.8% |
| Fingerprint | 105,393 | 1,766,489 | 5.6% |
Conclusion
I think that it might be interesting to apply this analysis to the various Hubs in the whole DPLA dataset to see if there is anything interesting to be seen across the various types of content providers.
I’m also curious if there are other kinds of normalizations that would be logical to apply to the subjects that I’m blanking on. One that I would probably want to apply at some point is the normalization for LCSH that splits a subject into its parts if it has the double hype — in the string. I wrote about the effect on the subjects for the DPLA dataset in a previous post.
As always feel free to contact me via Twitter if you have questions or comments.
Pingback: Article #6: Metadata Normalization As an Indicator of Quality? – E. D. Lynch
Pingback: andere.strikingly.com