For the past few weeks I’ve been curious about the punctuation characters that are being used in the subject strings in the DPLA dataset I’ve been using for some blog posts over the past few months.
This post is an attempt to find out the range of punctuation characters used in these subject strings and is carried over from last week’s post related to subject string metrics.
What got me started was that in the analysis used for last week’s post, I noticed that there were a number of instances of em dashes “—” (528 instances) and en dashes “–” (822 instances) being used in place of double hyphens “–” in subject strings from The Portal to Texas History. No doubt these were most likely copied from some other source. Here is a great subject string that contains all three characters listed above.
Real Property — Texas –- Zavala County — Maps
Turns out this isn’t just something that happened in the Portal data, here is an example from the Mountain West Digital Library.
Highway planning--Environmental aspects–Arizona—Periodicals
To get the analysis started the first thing that I need to do is establish what I’m considering punctuation characters because that definition can change depending on who you are talking to and what language you are using. For this analysis I’m using the punctuation listed in the python string module.
>>> import string
>>> print string.punctuation
!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
So this gives us 32 characters that I’m considering to be punctuation characters for the analysis in this post.
The first thing I wanted to do was to get an idea of which of the 32 characters were present in the subject strings, and how many instances there were. In the dataset I’m using there are 1,871,877 unique subject strings. Of those subject strings 1,496,769 or 80% have one or more punctuation characters present.
Here is the breakdown of the number of subjects that have a specific character present. One thing to note is that when processing if there were repeated instance of a character, they were reduced to a single instance, it doesn’t affect the analysis just something to note.
| Character | Subjects with Character |
| ! | 72 |
| “ | 1,066 |
| # | 432 |
| $ | 57 |
| % | 16 |
| & | 33,825 |
| ‘ | 22,671 |
| ( | 238,252 |
| ) | 238,068 |
| * | 451 |
| + | 81 |
| , | 607,849 |
| – | 954,992 |
| . | 327,404 |
| / | 3,217 |
| : | 10,774 |
| ; | 5,166 |
| < | 1,028 |
| = | 1,027 |
| > | 1,027 |
| ? | 7,005 |
| @ | 53 |
| [ | 9,872 |
| ] | 9,893 |
| \ | 32 |
| ^ | 1 |
| _ | 80 |
| ` | 99 |
| { | 9 |
| | | 72 |
| } | 9 |
| ~ | 4 |
One thing that I found interesting is that characters () and [] have different numbers of instances suggesting there are unbalanced brackets and parenthesis in subjects somewhere.
Another interesting note is that there are 72 instances of subjects that use the pipe character “|”. The pipe is often used by programmers and developers as a delimiter because it “is rarely used in the data values” this analysis says that while true it is rarely used, it should be kept in mind that it is sometimes used.
Next up was to look at how punctuation was distributed across the various Hubs.
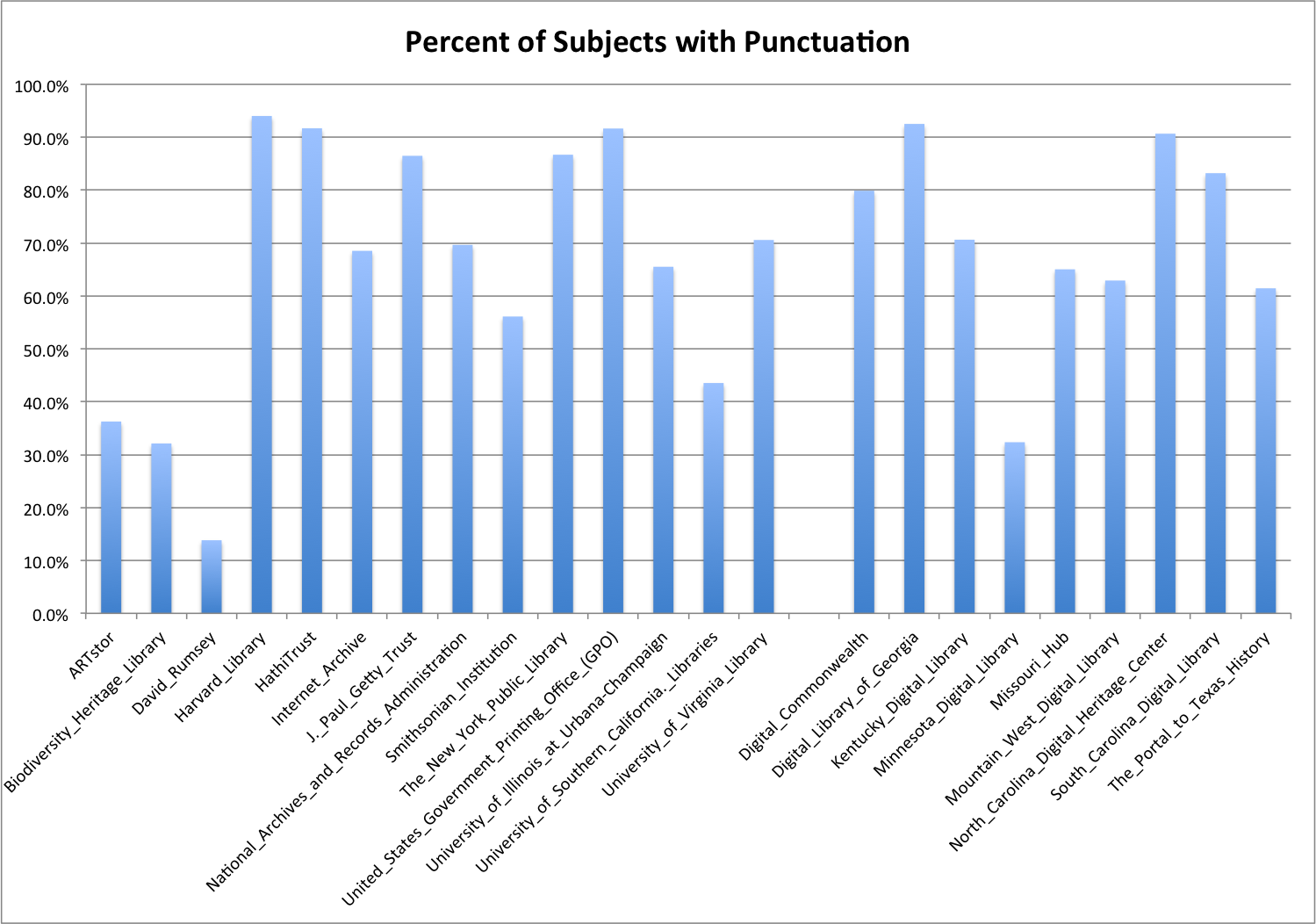
In the table below I’ve pulled out the total number of unique subjects per Hub in the DPLA dataset. I show the number of subjects without punctuation and the number of subjects with some sort of punctuation and finally display the percentage of subjects with punctuation.
| Hub Name | Unique Subjects | Subjects without Punctuation | Subjects with Punctuation | Percent with Punctuation |
| ARTstor | 9,560 | 6,093 | 3,467 | 36.3% |
| Biodiversity_Heritage_Library | 22,004 | 14,936 | 7,068 | 32.1% |
| David_Rumsey | 123 | 106 | 17 | 13.8% |
| Harvard_Library | 9,257 | 553 | 8,704 | 94.0% |
| HathiTrust | 685,733 | 56,950 | 628,783 | 91.7% |
| Internet_Archive | 56,910 | 17,909 | 39,001 | 68.5% |
| J._Paul_Getty_Trust | 2,777 | 375 | 2,402 | 86.5% |
| National_Archives_and_Records_Administration | 7,086 | 2,150 | 4,936 | 69.7% |
| Smithsonian_Institution | 348,302 | 152,850 | 195,452 | 56.1% |
| The_New_York_Public_Library | 69,210 | 9,202 | 60,008 | 86.7% |
| United_States_Government_Printing_Office_(GPO) | 174,067 | 14,525 | 159,542 | 91.7% |
| University_of_Illinois_at_Urbana-Champaign | 6,183 | 2,132 | 4,051 | 65.5% |
| University_of_Southern_California._Libraries | 65,958 | 37,237 | 28,721 | 43.5% |
| University_of_Virginia_Library | 3,736 | 1,099 | 2,637 | 70.6% |
| Digital_Commonwealth | 41,704 | 8,381 | 33,323 | 79.9% |
| Digital_Library_of_Georgia | 132,160 | 9,876 | 122,284 | 92.5% |
| Kentucky_Digital_Library | 1,972 | 579 | 1,393 | 70.6% |
| Minnesota_Digital_Library | 24,472 | 16,555 | 7,917 | 32.4% |
| Missouri_Hub | 6,893 | 2,410 | 4,483 | 65.0% |
| Mountain_West_Digital_Library | 227,755 | 84,452 | 143,303 | 62.9% |
| North_Carolina_Digital_Heritage_Center | 99,258 | 9,253 | 90,005 | 90.7% |
| South_Carolina_Digital_Library | 23,842 | 4,002 | 19,840 | 83.2% |
| The_Portal_to_Texas_History | 104,566 | 40,310 | 64,256 | 61.5% |
To make it a little easier to see I make a graph of this same data and divided the graph into two groups, on the left are the Content-Hubs and the right are the Service-Hubs.
Percent of Subjects with Punctuation
I don’t see a huge difference between the two groups and the percentage of punctuation in subjects, at least by just looking at things.
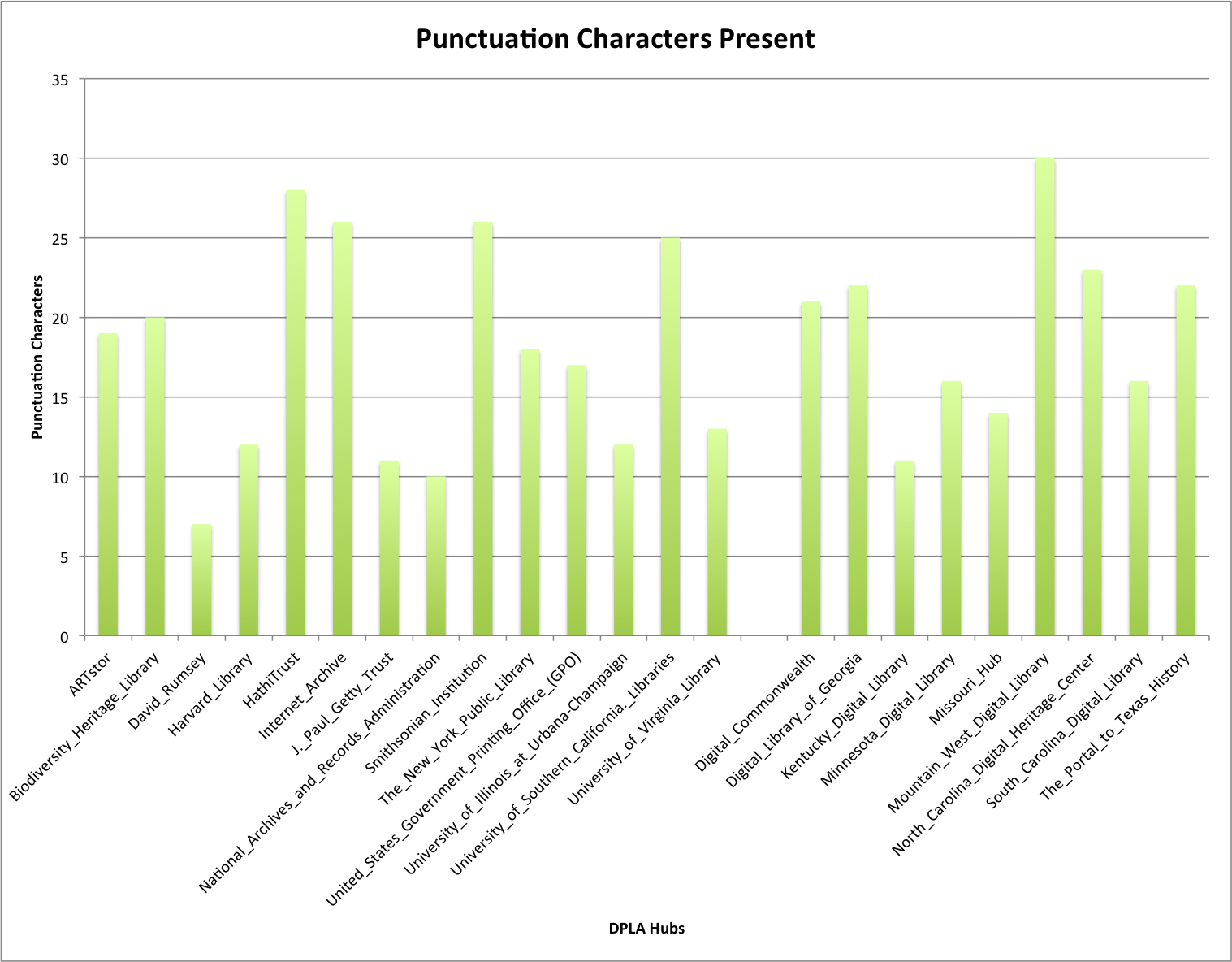
Next I wanted to see out of the 32 characters that I’m considering in this post, how many of those characters are present in a given hubs subjects. That data is in the table and graph below.
| Hub Name | Characters Present |
| ARTstor | 19 |
| Biodiversity_Heritage_Library | 20 |
| David_Rumsey | 7 |
| Digital_Commonwealth | 21 |
| Digital_Library_of_Georgia | 22 |
| Harvard_Library | 12 |
| HathiTrust | 28 |
| Internet_Archive | 26 |
| J._Paul_Getty_Trust | 11 |
| Kentucky_Digital_Library | 11 |
| Minnesota_Digital_Library | 16 |
| Missouri_Hub | 14 |
| Mountain_West_Digital_Library | 30 |
| National_Archives_and_Records_Administration | 10 |
| North_Carolina_Digital_Heritage_Center | 23 |
| Smithsonian_Institution | 26 |
| South_Carolina_Digital_Library | 16 |
| The_New_York_Public_Library | 18 |
| The_Portal_to_Texas_History | 22 |
| United_States_Government_Printing_Office_(GPO) | 17 |
| University_of_Illinois_at_Urbana-Champaign | 12 |
| University_of_Southern_California._Libraries | 25 |
| University_of_Virginia_Library | 13 |
Here is this data in a graph grouped in Content and Service Hubs.
Unique Punctuation Characters Present
Mountain West Digital Library had the most characters covered with 30 of the 32 possible punctuation characters. One the low end was the David Rumsey collection with only 7 characters represented in the subject data.
The final thing is to see the character usage for all characters divided by hub so the following graphic presents that data. I tried to do a little coloring of the table to make it a bit easier to read, don’t know how well I accomplished that.
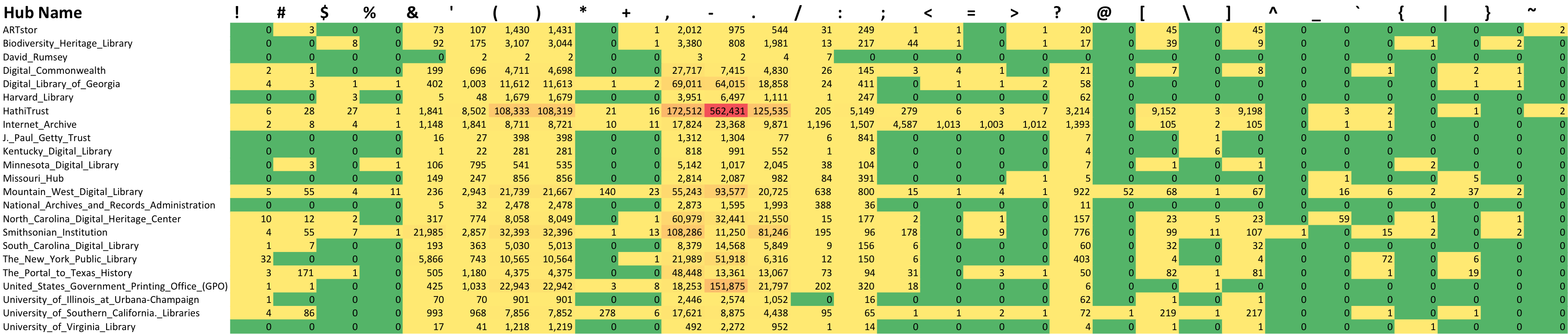
Punctuation Character Usage (click to view larger image)
So it looks like the following characters ‘(),-. are present in all of the hubs. The characters %/?: are present in almost all of the hubs (missing one hub each).
The least used character is the ^ which is only in use by one hub in one record. The characters ~ and @ are only used in two hubs each.
I’ve found this quick look at the punctuation usage in subjects pretty interesting so far, I know that there were some anomalies that I unearthed for the Portal dataset with this work that we now have on the board to fix, they aren’t huge issues but things that probably would stick around for quite some time in a set of records without specific identification.
For me the next step is to see if there is a way to identify punctuation characters that are used incorrectly and be able to flag those fields and records in some way to report back to metadata creators.
Let me know what you think via Twitter if you have questions or comments.