In my last post I started looking at some of the data from the End of Term 2012 Web Archive snapshot that we have at the UNT Libraries. For more information about EOT2012 take a look at that previous post.
EOT2008 PDFs
From the EOT2008 Web archive I had extracted the 4,489,675 unique (by hash) PDF files that were present and carried out a bit of analysis on them as a whole to see if there was anything interesting I could tease out. The results of that investigation I presented at an IS&T Archiving conference a few years back. The text from the proceedings for that submission is here and the slides presented are here.
Moving forward several years, I was curious to see how many of those nearly 4.5 million PDFs were still around in 2012 when we crawled the federal Web again as part of the EOT2012 project.
I used the same hash dataset from the previous post to do this work which made things very easy. I first pulled the hash values for the 4.489,675 PDF files from EOT2008. Next I loaded all of the hash values from the EOT2012 crawls. The next and final step was to iterate through each of the PDF file hashes and do a lookup to see if that content hash is present in the EOT2012 hash dataset. Pretty straightforward.
Findings
After the numbers finished running, it looks like we have the following.
| PDFs | Percentage | |
| Found | 774,375 | 17% |
| Missing | 3,715,300 | 83% |
| Total | 4,489,675 | 100% |
Put into a pie chart where red equals bad.
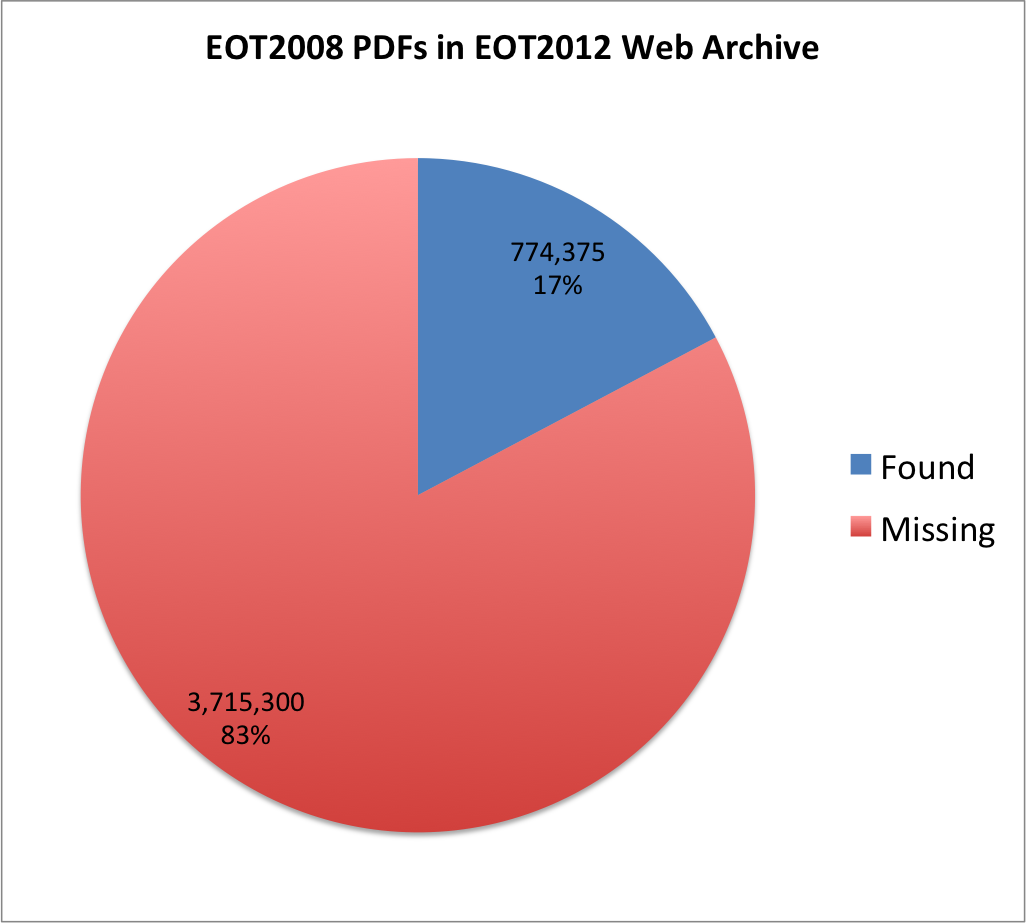
EOT2008 PDFs in EOT2012 Archive
So 83% of the PDF files that were present in 2008 are not present in the EOT2012 Archive.
With a little work it wouldn’t be hard to see how many of these PDFs are still present on the web today at the same URL as in 2008. I would imagine it is a much smaller number than the 17%.
A thing to note about this is that because I am using content hashes and not URLs, it is possible that an EOT2008 PDF is available at a different URL entirely in 2012 when it was harvested again. So the URL might not be available but the content could be available at another location.
If you have questions or comments about this post, please let me know via Twitter.
Pingback: The Internet Archive aims to preserve 100 terabytes of government website data… just in case | GamingSoFun
Pingback: Preserving U.S. Government Websites and Data as the Obama Term Ends | Internet Archive Blogs
Pingback: Obama Admin. Web Page Preservation | Daily Amin - Regional, National & International - Breaking News, World News, Sports News, Photo and Video News
Pingback: Obama Admin. Web Page Preservation | Florida News
Pingback: Archivers Busy Preserving Obama Admin.’s Web Pages | Newstories
Pingback: Obama Admin. Web Page Preservation - The USA Times |US News,World News, Politics, Economics, Entertainment,Sport,Business & Finance | The USA Times |US News,World News, Politics, Economics, Entertainment,Sport,Business & Finance
Pingback: Obama Admin. Web Page Preservation – WordPress
Pingback: The Internet Archive aims to preserve 100 terabytes of government website data… just in case - techsqrd.com
Pingback: » לקראת טראמפ: יוזמה לגיבוי מידע סביבתי ממשלתי ועותק של ארכיון האינטרנט בקנדה
Pingback: The Internet Archive launches Wayback Machine Chrome extension to combat link rot – Game News
Pingback: The Internet Archive launches Wayback Machine Chrome extension to combat link rot – Marketmonitor
Pingback: The Internet Archive launches Wayback Machine Chrome extension to combat link rot - techsqrd.com
Pingback: The Internet Archive launches Wayback Machine Chrome extension to combat link rot – Nocturnal Zine
Pingback: The Bureau of Vanished Documents • The Golden Assay
Pingback: Efforts to Save Online Government Data for Public Access - LRC - orbit
Pingback: The Internet Archive has preserved 200TB of government website data during transition to Trump administration - LI Tech News
Pingback: The Internet Archive has preserved 200TB of government website data during transition to Trump administration » Best Products Review
Pingback: The Internet Archive has preserved 200TB of government website data during transition to Trump administration – Marketmonitor
Pingback: The Internet Archive has preserved 200TB of government website data during transition to Trump administration | Ask Ms AC Kennedy
Pingback: The Internet Archive has preserved 200TB of government website data during transition to Trump administration - techsqrd.com
Pingback: Government Data At Risk – UC3 Portal