This is another post in a series that I’ve been doing to compare the End of Term Web Archives from 2008 and 2012. If you look back a few posts in this blog you will see some other analysis that I’ve done with the datasets so far.
One thing that I am interested in understanding is how well the group that conducted the EOT crawls did in relation to what I’m calling “curator intent”. For both the EOT archives suggested seeds were collected using instances of the URL Nomination Tool hosted by the UNT Libraries. A combination of bulk lists of seeds URLs collected by various institutions and individuals were combined individual nominations made by users of the nomination tool. The resulting lists were used as seed lists for the crawlers that were used to harvest the EOT archives. In 2008 there were four institutions that crawled content, the Internet Archive (IA), Library of Congress (LOC), California Digital Library (CDL), and the UNT Libraries (UNT). In 2012 CDL was not able to do any crawling so just IA, LOC and UNT crawled. UNT and LOC had limited scope in what they were interested in crawling while CDL and IA took the entire seed list and used that to feed their crawlers. The crawlers were scoped very wide so that they would get as much content as they could, so the nomination seeds were used as starting places and we allowed the crawlers to go to all subdomains and paths on those sites as well as to areas that the sites linked to on other domains.
During the capture period there wasn’t consistent quality control performed for the crawls, we accepted what we could get and went on with our business.
Looking back at the crawling that we did I was curious of two things.
- How many of the domain names from the nomination tool were not present in the EOT archive.
- How many domains from .gov and .mil were captured but not explicitly nominated.
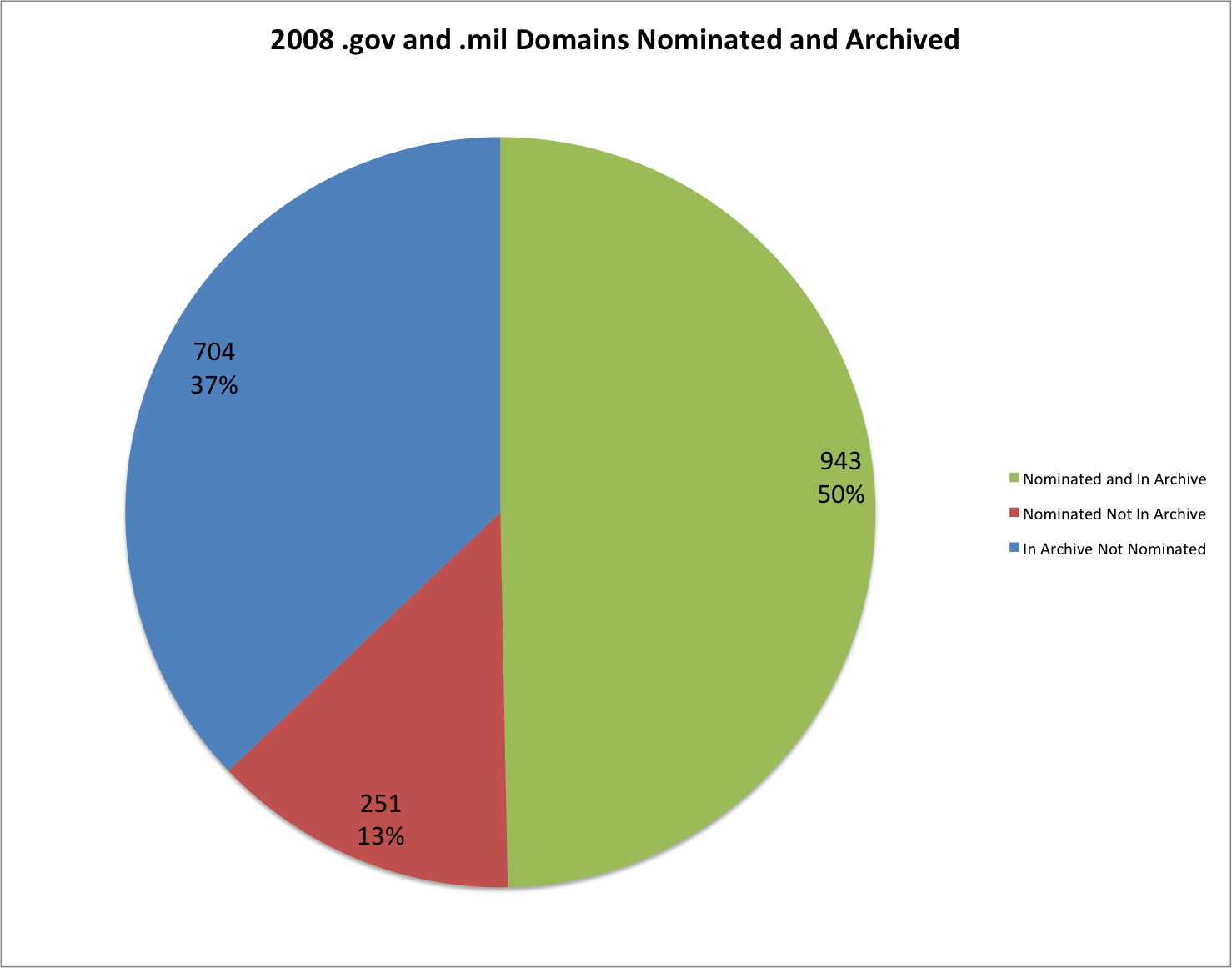
EOT2008 Nominated vs Captured Domains.
In the 2008 nominated URL list form the URL Nomination Tool there were a total of 1,252 domains with 1,194 being either .gov or .mil. In the EOT2008 archive there were a total of 87,889 domains and 1,647 of those were either .gov or .mil.
There are 943 domains that are present in both the 2008 nomination list and the EOT2008 archive. There are 251 .gov or .mil domains from the nomination list that were not present in the EOT2008 archive. There are 704 .gov or .mil domains that are present in the EOT2008 archive but that aren’t present in the 2008 nomination list.
Below is a chart showing the nominated vs captured for the .gov and .mil
2008 .gov and .mil Nominated and Archived
Of those 704 domains that were captured but never nominated, here are the thirty most prolific.
| Domain | URLs |
| womenshealth.gov | 168,559 |
| dccourts.gov | 161,289 |
| acquisition.gov | 102,568 |
| america.gov | 89,610 |
| cfo.gov | 83,846 |
| kingcounty.gov | 61,069 |
| pa.gov | 42,955 |
| dc.gov | 28,839 |
| inl.gov | 23,881 |
| nationalservice.gov | 22,096 |
| defenseimagery.mil | 21,922 |
| recovery.gov | 17,601 |
| wa.gov | 14,259 |
| louisiana.gov | 12,942 |
| mo.gov | 12,570 |
| ky.gov | 11,668 |
| delaware.gov | 10,124 |
| michigan.gov | 9,322 |
| invasivespeciesinfo.gov | 8,566 |
| virginia.gov | 8,520 |
| alabama.gov | 6,709 |
| ct.gov | 6,498 |
| idaho.gov | 6,046 |
| ri.gov | 5,810 |
| kansas.gov | 5,672 |
| vermont.gov | 5,504 |
| arkansas.gov | 5,424 |
| wi.gov | 4,938 |
| illinois.gov | 4,322 |
| maine.gov | 3,956 |
I see quite a few state and local governments that have a .gov domain which was out of scope of the EOT project but there are also a number of legitimate domains in the list that were never nominated.
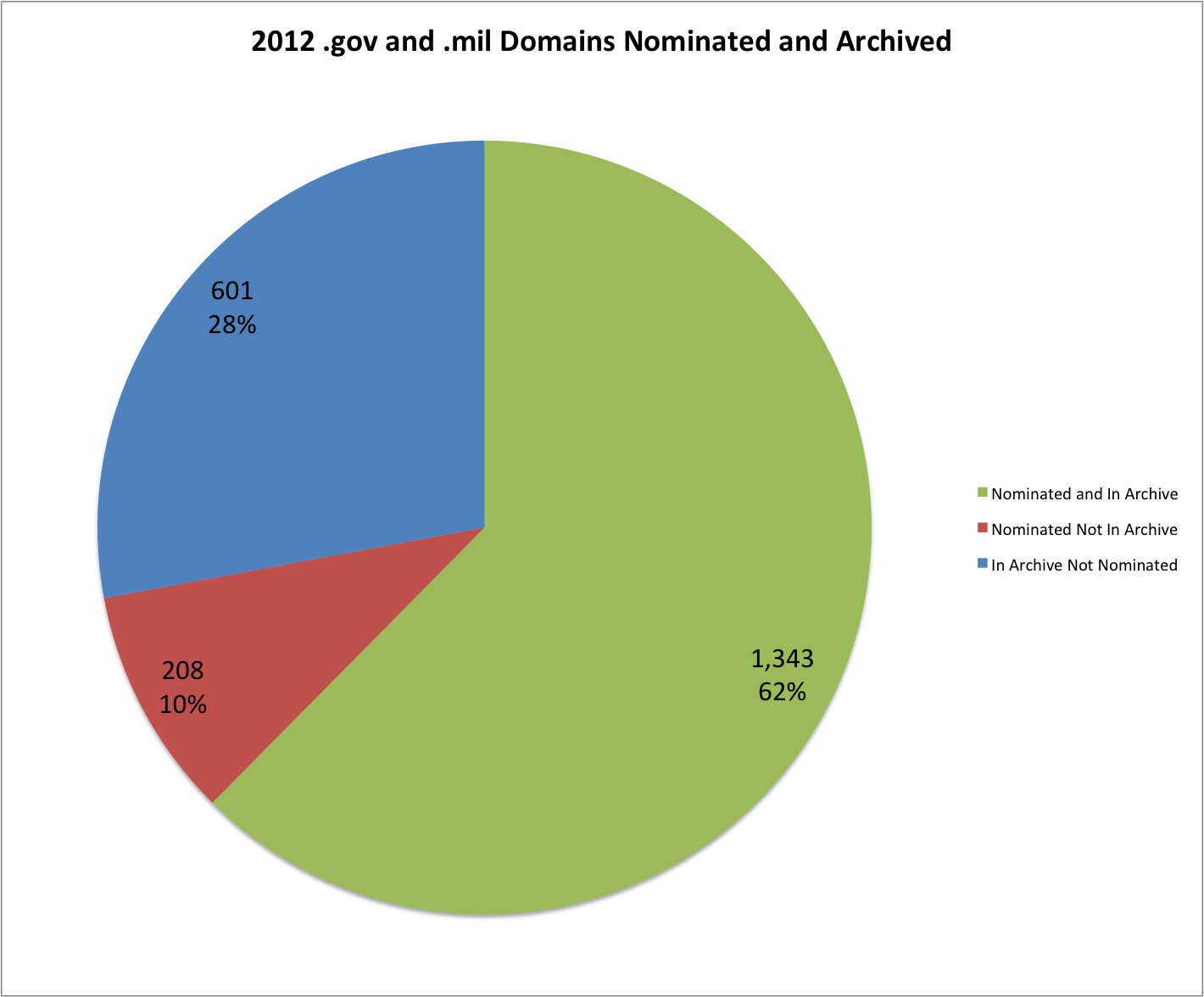
EOT2012 Nominated vs Captured Domains.
In the 2012 nominated URL list form the URL Nomination Tool there were a total of 1,674 domains with 1,551 of those being .gov or .mil domains. In the EOT2012 archive there were a total of 186,214 domains and 1,944 of those were either .gov or .mil.
There are 1,343 domains that are present in both the 2008 nomination list and the EOT2012 archive. There are 208 .gov or .mil domains from the nomination list that were not present in the EOT2012 archive. There are 601 .gov or .mil domains that are present in the EOT2012 archive but that aren’t present in the 2012 nomination list.
Below is a chart showing the nominated vs captured for the .gov and .mil
2012 .gov and .mil Domains Nominated and Archived
Of those 601 domains that were captured but never nominated, here are the thirty most prolific.
| Domain | URLs |
| gao.gov | 952,654 |
| vaccines.mil | 856,188 |
| esgr.mil | 212,741 |
| fdlp.gov | 156,499 |
| copyright.gov | 70,281 |
| congress.gov | 40,338 |
| openworld.gov | 31,929 |
| americaslibrary.gov | 18,415 |
| digitalpreservation.gov | 17,327 |
| majorityleader.gov | 15,931 |
| sanjoseca.gov | 10,830 |
| utah.gov | 9,387 |
| dc.gov | 9,063 |
| nyc.gov | 8,707 |
| ng.mil | 8,199 |
| ny.gov | 8,185 |
| wa.gov | 8,126 |
| in.gov | 8,011 |
| vermont.gov | 7,683 |
| maryland.gov | 7,612 |
| medicalmuseum.mil | 7,135 |
| usbg.gov | 6,724 |
| virginia.gov | 6,437 |
| wv.gov | 6,188 |
| compliance.gov | 6,181 |
| mo.gov | 6,030 |
| idaho.gov | 5,880 |
| nv.gov | 5,709 |
| ct.gov | 5,628 |
| ne.gov | 5,414 |
Again there are a number of state and local government domains present in the list but up at the top we see quite a few URLs harvested from domains that are federal in nature and would fit into the collection scope for the EOT project.
How did we do?
The way that seed lists for the nomination tool were collected for the EOT2008 and EOT2012 nomination lists introduced a bit of dirty data. We would need to look a little deeper to see what the issues were with these. Some things that come to mind are that we got seeds from domains that existed prior to 2008 or 2012 but that didn’t exist when we were harvesting. Also there could have been typos in the URLs that were nominated so we never grabbed the suggested content. We might want to introduce a validate process for the nomination tool that let’s us know what that status of a URL in a project is at a given point so that we can at least have some sort of record.
13% to 10%