The quality of metadata records for digital library objects is a subject that comes up pretty often at work. We haven’t stumbled upon any solid answers to overall questions about measuring, improving, or evaluating metadata but we have given a few things a try. Here are a few examples of one of these components that we have found useful.
UNTL Metadata
The UNT Libraries’ Digital Collections consists of The Portal to Texas History, the UNT Digital Library, and The Gateway to Oklahoma History. At the time of writing this post we have 1,049,483 metadata records in our metadata store. Our metadata model uses the primary fifteen Dublin Core Metadata Elements which we describe as “locally qualified” so for example a Title with a qualifier of “Main Title”, or “Added Title” and a Subject that is a namedPerson or LCSH, or MESH. In addition to those fifteen elements we have added a few other qualified fields such as Citation, Degree, Partner, Collection, Primary Source, Note, and Meta. These all make up a metadata format we call locally UNTL. This is all well documented by our Digital Projects Unit on our Metadata Guidelines pages. All of the controlled vocabularies we use as qualifiers to our metadata elements are available in our Controlled Vocabularies App . We typically serialize our metadata format as an XML record on disk, each item in our system exposes the raw UNTL metadata record in addition to other formats. Here is an example record for an item in The Portal. To simplify the reading, writing and processing of metadata records in our system we have a Python module called pyuntl that we use for all things UNTL metadata related.
Completeness
The group of folks in the Digital Libraries Division that were interested in metadata quality have been talking about ways to measure quality in our systems for some time. As the conversation isn’t new, we have quite a bit of literature on the subject to review. We noticed that when librarians begin to talk about “qualify of metadata” we tend to get a bit bristly, saying “well what really is quality” and “but not in all situations” and so on. We wanted to come up with a metric that we could use as a demonstration of the value of defining some of the concepts of quality and moving them into a system in an actionable way. We decided that a notion of completeness could be a good way of moving forward because when defining what were the required fields for a record, it would be easy to assess in a neutral fashion if a metadata has the required fields or not.
For our completeness metric we identified the following fields as needing to be present in a metadata record in order for us to consider it a “minimally viable record” in our system.
- Title
- Description
- Subject/Keywords
- Language
- Collection
- Partner
- Resource Type
- Format
- Meta Information for Record
The idea was that even if one did not know much of anything about an object, that we would be able to describe it at the surface level, assign it a title, language value, subject/keyword and give it a resource type and format. The meta information about the item and the Institution and Collection elements are important for keeping track of where items come from, who owns them and to make the system work properly. We also assigned a weight to some of these fields saying that some of the elements carry more weight than others. Here is that breakdown.
- Title = 10
- Description = 1
- Subject/Keywords = 1
- Language = 1
- Collection = 1
- Partner = 10
- Resource Type = 5
- Format = 1
- Meta Information for Record = 20
The pyuntl library has functionality built into it that calculates a completeness score from 0.0 to 1.0 based on these weights with a record with a score of 1.0 beings “complete” or at least “minimally viable” and records with a score lower than 1.0 being deficient in some way.
In addition to this calculated metric we try and provide metadata creators with visual cues indicating that a “required” field is missing or partial. The image below is an example of what is shown to a metadata editor as they are creating metadata records.
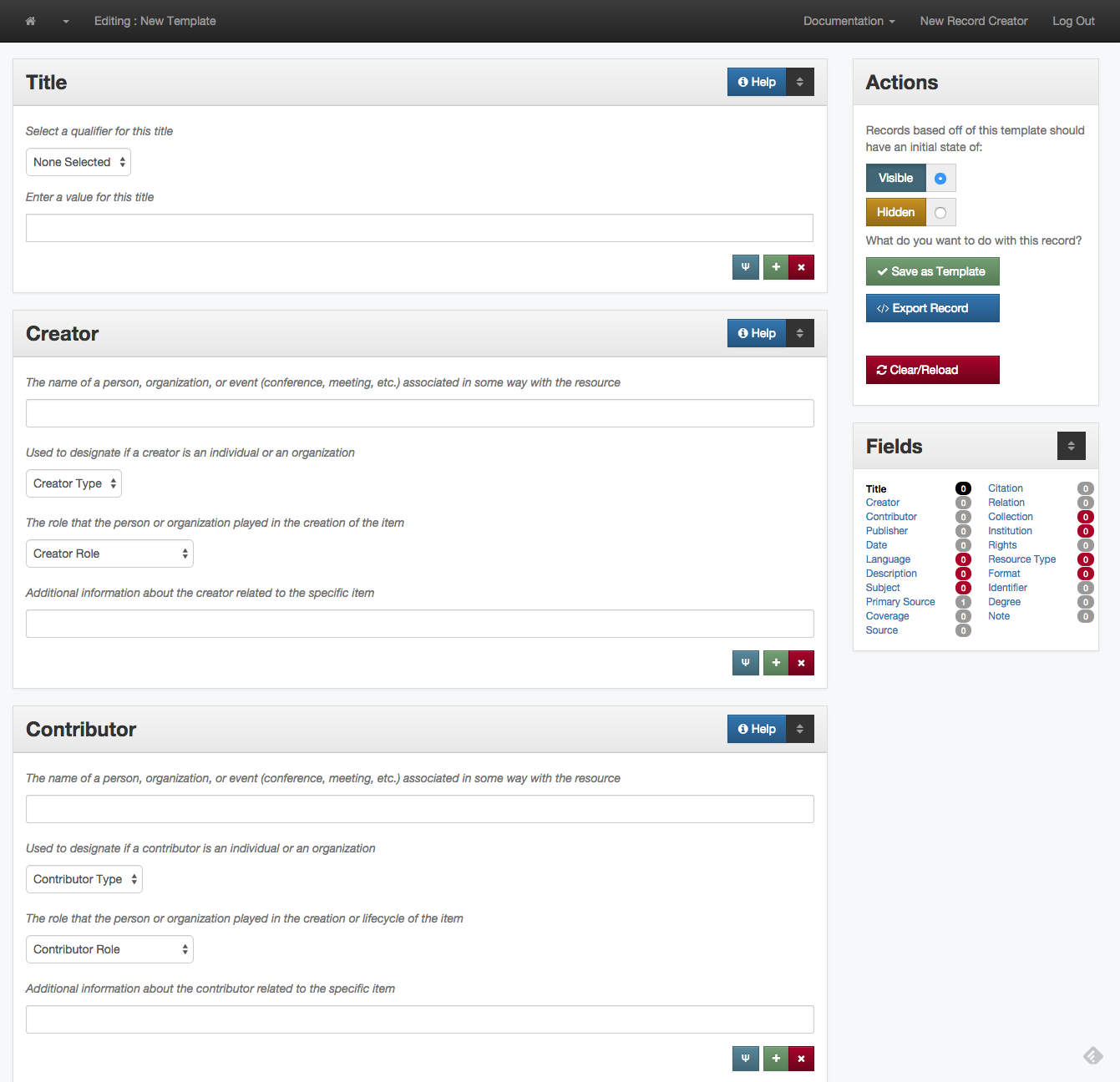
Metadata Editing Interface for the UNT Libraries
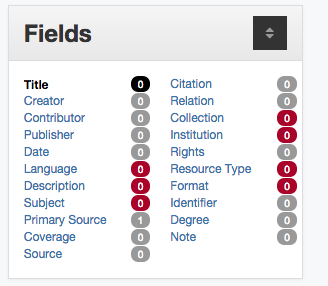
Detail of fields sidecar for uncompleted metadata record
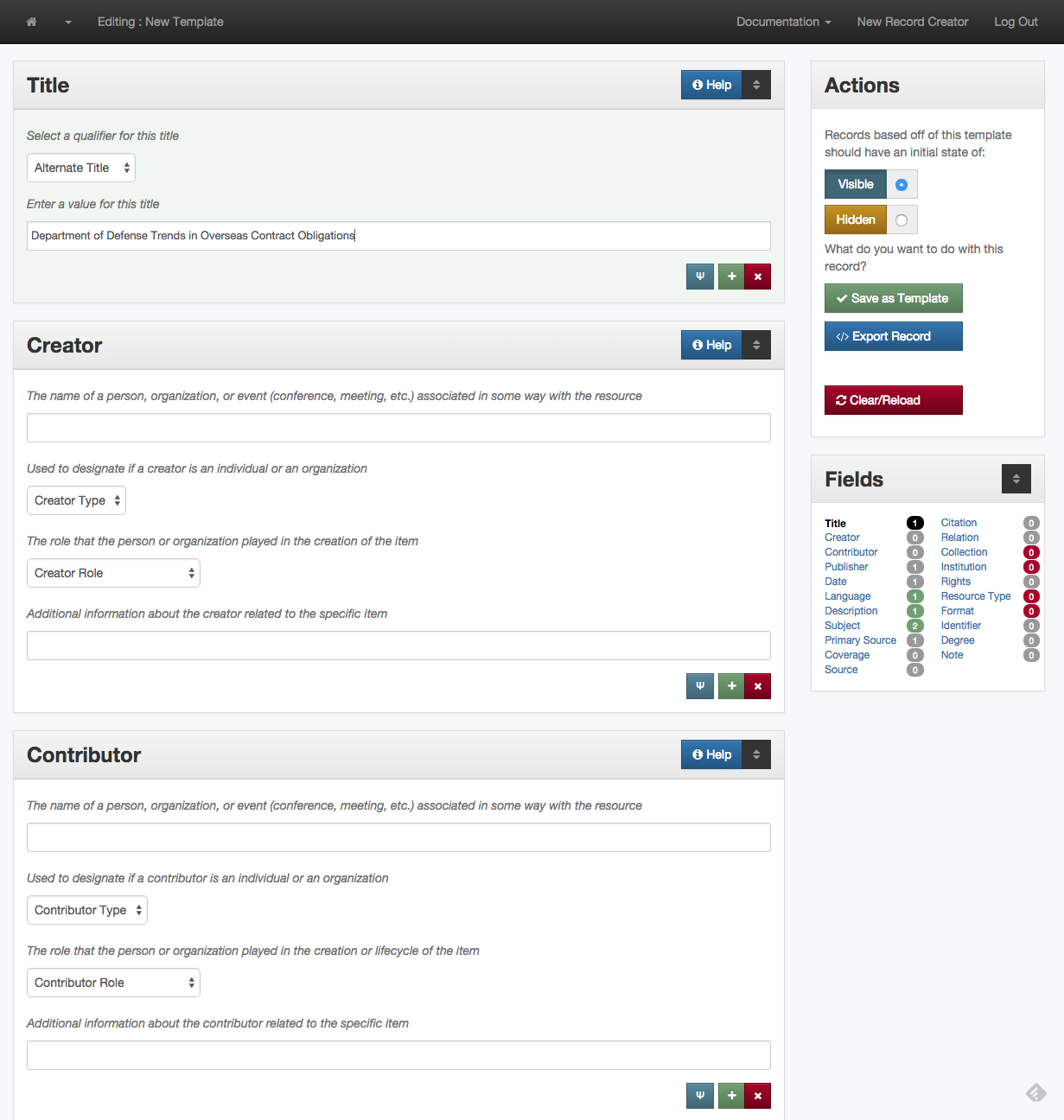
Metadata editing interface for partially completed record in the UNT Libraries Digital Collections
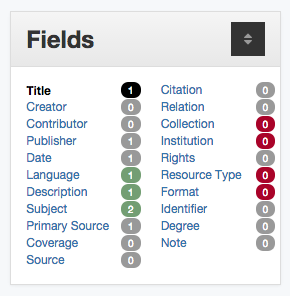
Detail of fields sidecar for partially completed metadata record.
Our hope is that by providing this information to metadata creators, they will know when they have created at least a minimally viable metadata record, or if they pull up a record to edit that is not “complete” that they can quickly assess and fix the problem.
When we are indexing our items into our search system we calculate and store this metric so that we can take a look at our metadata records as a whole and see how we are doing. While we currently only use this metric behind the scenes, we are hoping to move it more front and center in the metadata editing interface. As it stands today here is the breakdown of records in the system.
| Completeness Score | Number of Records |
| 1.0 | 1,007,503 |
| 0.9830508 | 17,307 |
| 0.9661017 | 12,142 |
| 0.9491525 | 12,526 |
| 0.9322034 | 1 |
| 0.7966102 | 3 |
| 0.779661 | 1 |
As can be seen there is still quite a bit of cleanup to be done on the records in the system in order to make the whole dataset “minimally viable” but it is pretty easy to identify which records are missing what now, and edit them accordingly. It can allow us to focus directly on metadata editing tasks which can be directly measured as “improvements” to the system a as a whole.
How are other institutions addressing this problem? Are we missing something? Hit me up on twitter if this is an area of interest.