The UNT Libraries has adopted the use of the Extended Date Time Format (EDTF) from the Library of Congress for our various digital library systems.
This allows us to use a machine readable notation to represent some of the date values that we run across in digital libraries (or libraries, archives and museums in general).
Things like
- circa 1922
- July 2014
- Winter 2000
- 3rd of July (maybe?) 1922
Which get preresented in EDTF as
- 1922~
- 2014-07
- 2000-24
- 1922-07?-03
I’ve been interested in working with date values in digital libraries for a while because they are one of the major ways that we try and slice our collections in an attempt to do interesting things with discovery, display and exploring.
The work that really got me thinking working with date values in metadata was Bitter Harvest: Problems & Suggested Solutions for OAI-PMH Data & Service Providers and the related Specifications for Metadata Processing Tools by Roy Tennant back in 2004 when he was at the California Digital Library working on a metadata aggregation and parsing project. Out of that project came an interesting Date Parsing Utility
In the Bitter Harvest paper referenced above the following list of dates was given by Roy as an example of the kinds of dates strings that are pretty normal to see in metadata in digital libraries.
- 1991-10-01
- ca. 1920.
- (ca). 1920)
- 2001.06.08 by CAD
- Unknown
- ca. June 19, 1901.
- (ca). June 19, 1901)
- [2001 or 2002.]
- 1853.
- c1875.
- c1908 November 19
- c1905
- 1929 June 6
- [between 1904 and 1908]
- [ca. 1967]
- 1918 ?
- [1919 ?]
- 191-?
- 1870 December, c1871
- 1920, 1921, 1922, 1923, 1924, 1925, 1926, 1927, 1928, 1929
We were seeing the same kinds of date values in our records and didn’t really have a sane way of dealing with them so we decided to become early adopters of the EDTF because it gave us a specification to follow to encode most of these kinds of date values.
In 2013 Hannah Tarver presented a paper at the Dublin Core Metadata Initiative conference in Lisbon titled Lessons Learned in Implementing the Extended Date/Time Format in a Large Digital Library that discussed some analysis we did at UNT over the 460,000 metadata records that were in the UNT Libraries Digital Collections at the Time. Poke around in that paper, it is kind of interesting (full disclosure, I’m a co-author so very biased)
Tools for working with EDTF
There are a few tools listed on the EDTF website for working with the EDTF date values. At UNT we developed one of these tools to use in our system and I wanted to talk a little about what it does and how it could be used by others.
We wrote a Python based EDTF Validator which will verify if a given string is in fact a valid EDTF string or if it is incorrectly formatted. The source for this validator is available on the UNT Libraries’ GitHub repository as the ExtendedDateTimeFormat.
In order to use this tool in our local systems we developed a simple JSON Web service that wraps the validation tool in an HTTP based API for validating these dates. You can interact with this service and read the documentation at the site Extended Date Time Format Levels 0, 1 and 2 Validation Service.
For the People Users
We use this service in our metadata editing tool everyday. When a user enters or adjust a date in a date field, the interface will call this Web service which in turn will return a True or False as to if the submitted date string is valid or invalid. We will present this information back to the user so that they know they need to adjust the formatting of the date string they supplied.
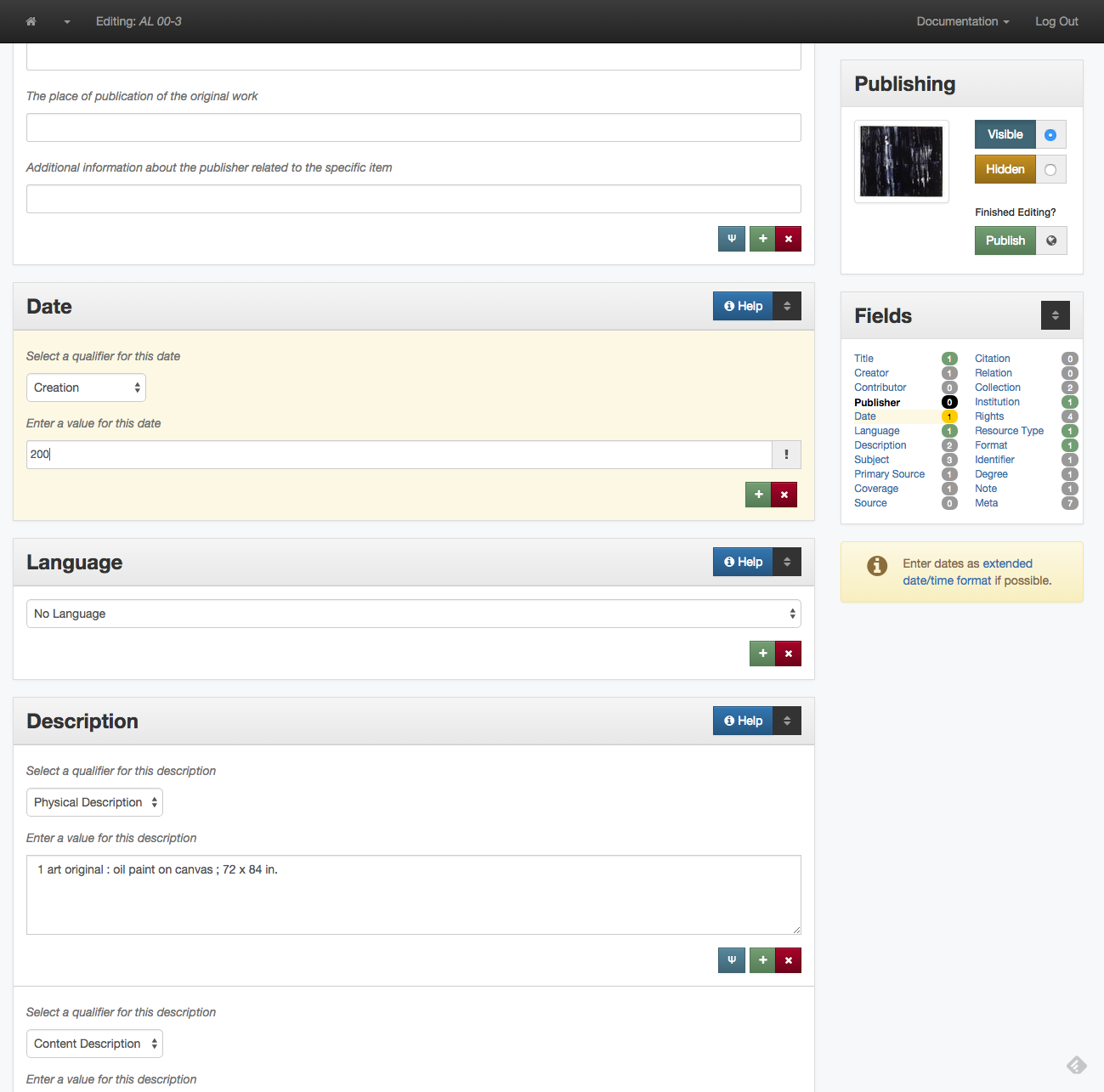
Invalid date notification in UNT Libraries Metadata Editor
The image above shows what the notification of an invalid date in the user interface looks like. If the date string is a valid EDTF then it will not produce any notification.
Because the EDTF is pretty foreign to most folks when they first get started using it we try and offer examples of how to notate common date concepts in our Descriptive Metadata Input Guidelines. You can view the date specific examples at this link.
For the Computer Users
We also make use of the ExtenededDateTimeFormat Python module directly when we index each record into our Solr index. We have a field “valid_dates” which is a boolean field with True set as the default value. While we index a record if the record has dates, each of the dates are validated against the EDTF validator. If any of them fail validation the field is stored with a False value instead of True. This allows us quickly to view the number of records which have invalid dates of some sort and work to remove them from the database. Once identified they can pretty easily be corrected.
For the Public Users
Finally we wanted to be able to turn some of these date strings into a more human readable format in our end user interfaces. EDTF is first a machine readable format which isn’t always obvious to people users. For example most people don’t really know what 2012-21 means and most actually struggle with 1999-04. For many of the easy to convert date strings we try and provide an equivalent for the user such as “Spring 2012” or “April 1999” instead. For the more complex strings we provide a link to a guide on how to interpret the EDTF used in our records.
Over the past few years we’ve found that the EDTF has worked well for a large majority of dates that we run into in our system. There are some concepts that are a little challenging to understand at first but in no time users are able to start using the EDTF to its fullest.
The next challenge that we don’t exactly have an answer to is exactly how some of these date strings should be indexed so that they can be faceted and sorted along with other more common ISO standard dates.
If you have any specific questions for me let me know on twitter.