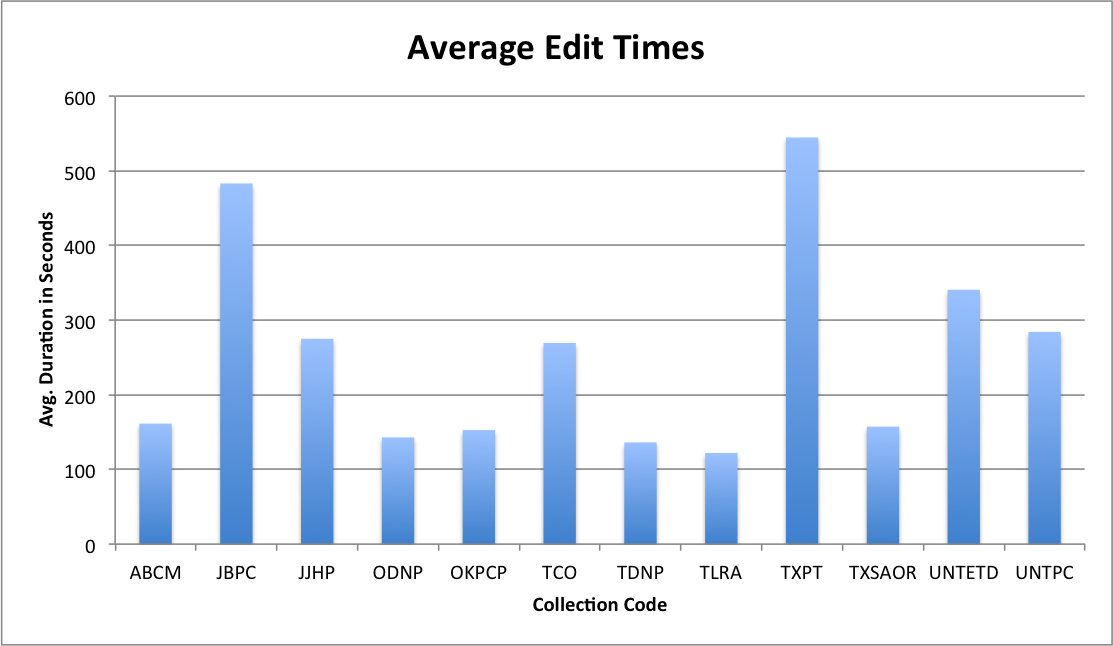
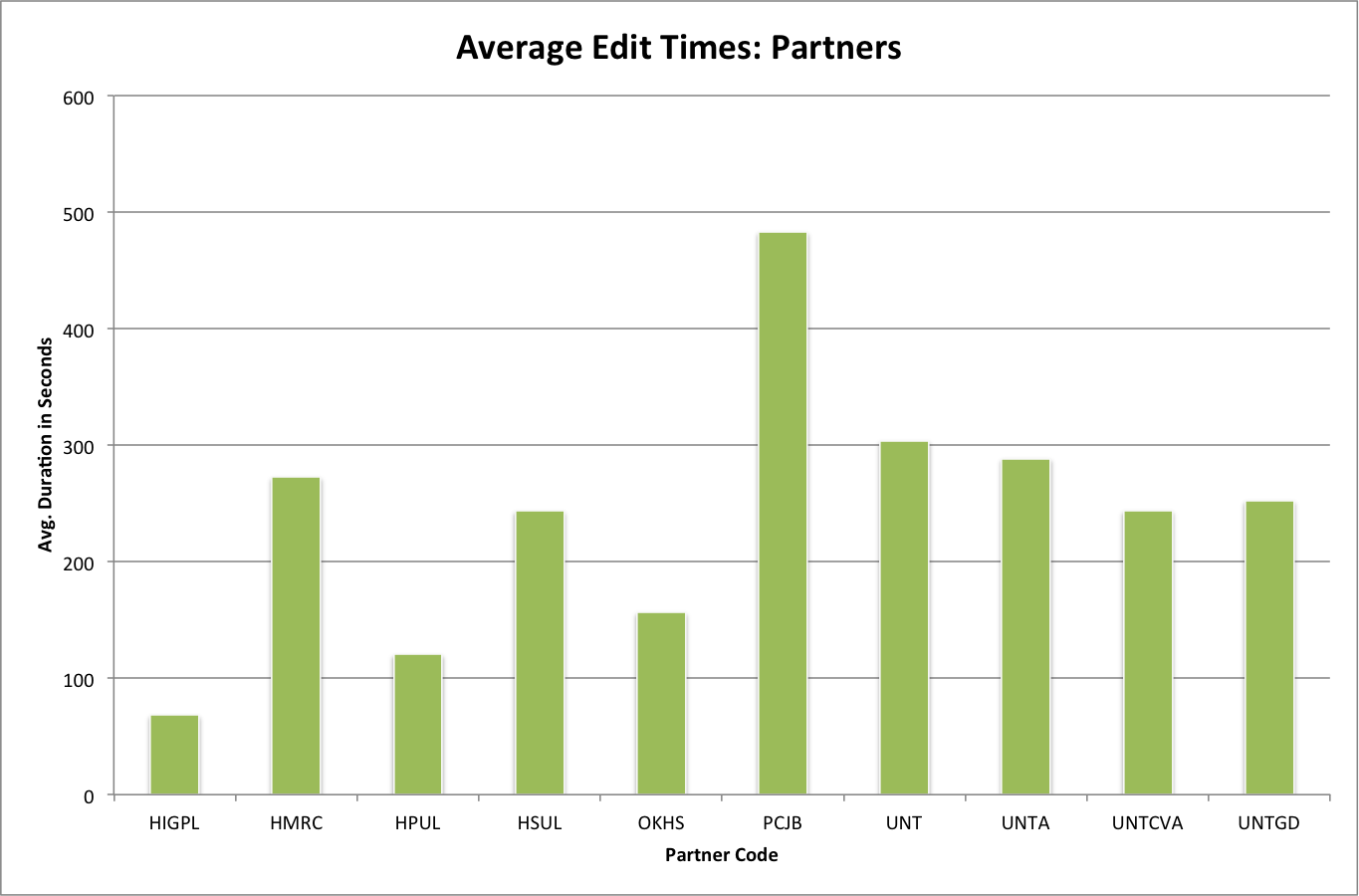
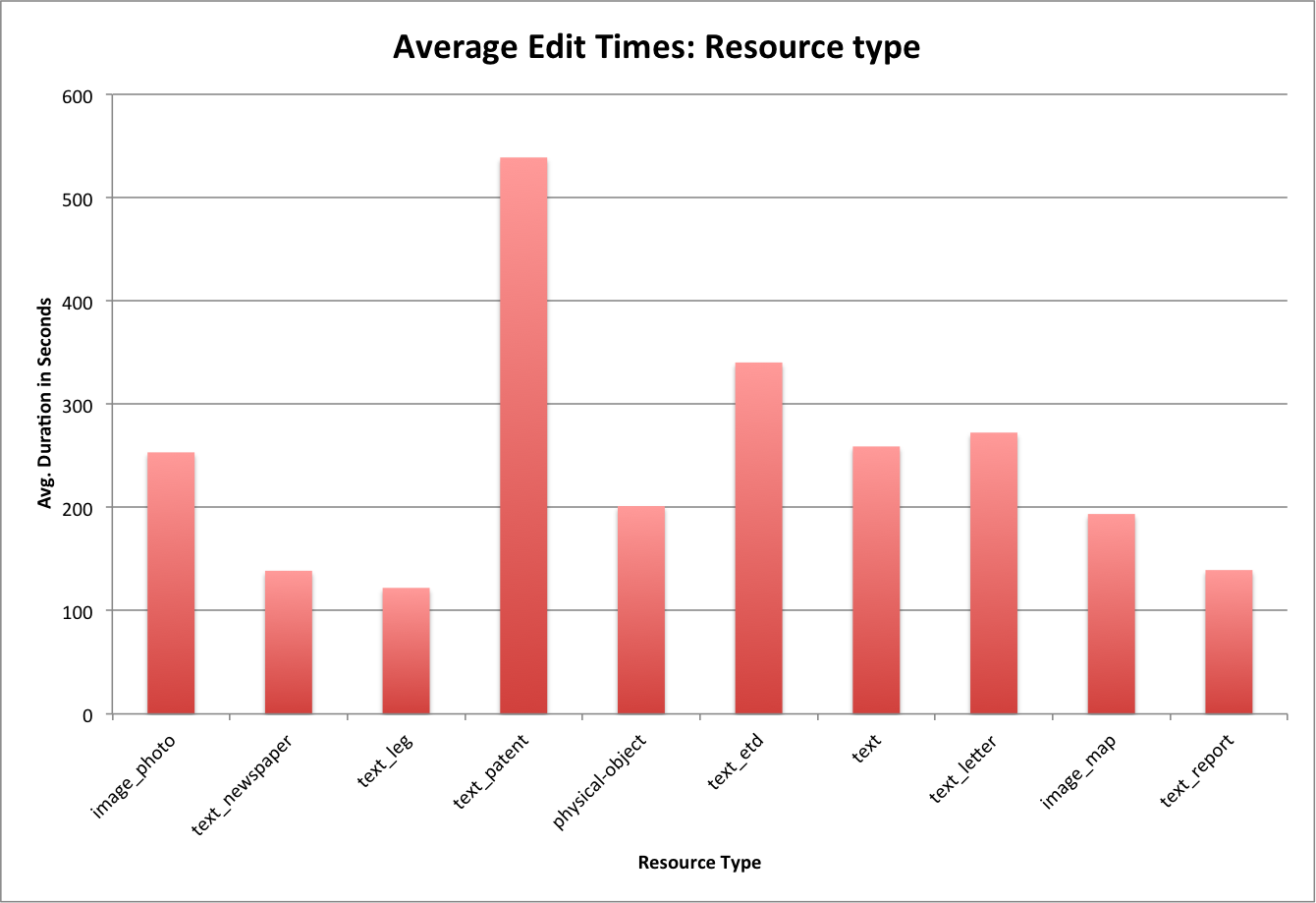
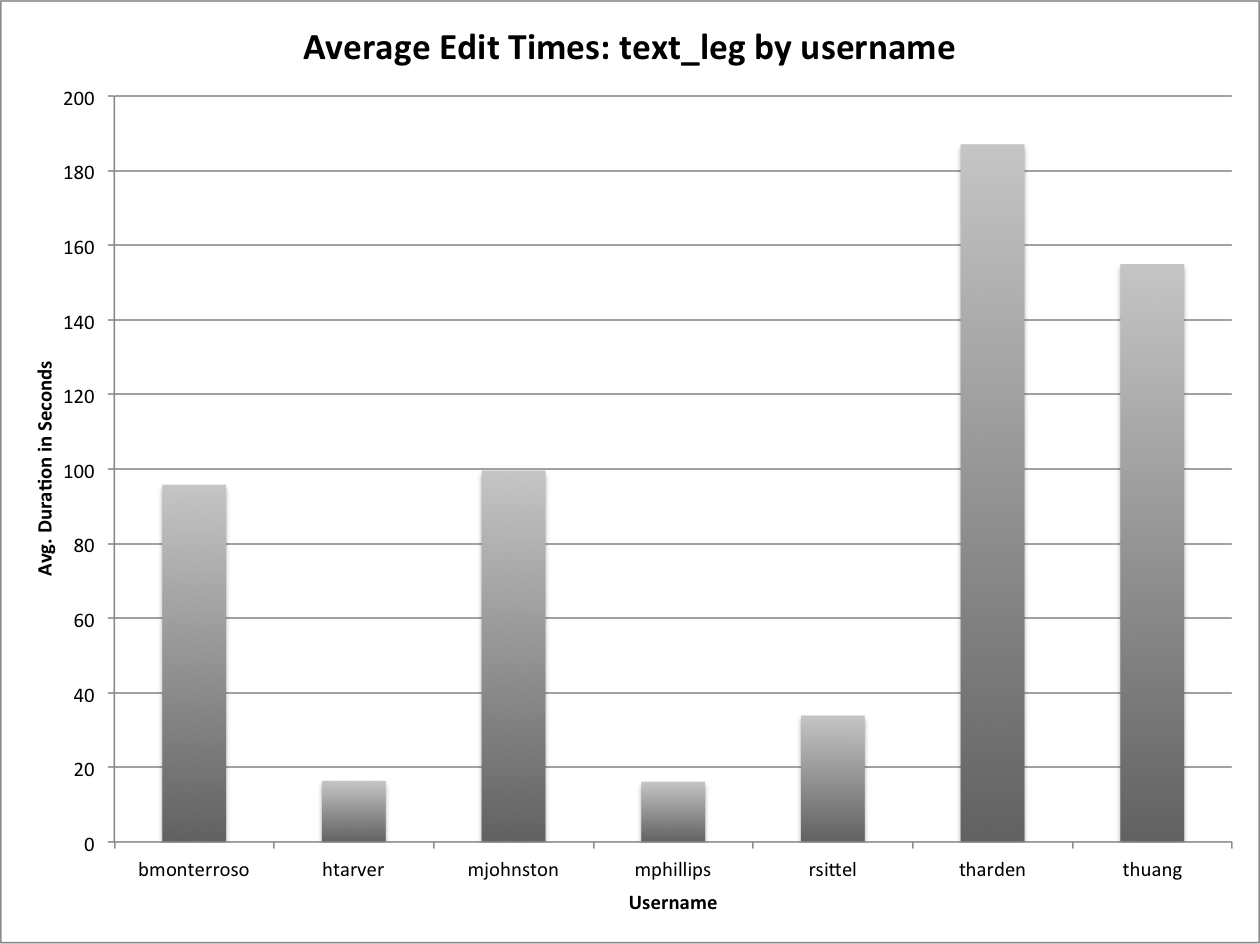
I had a question asked this last week about what was the most “used” item in our UNT Scholarly Works Repository, that led to discussion of the most “used” creator across that same collection. I spent a few minutes going through the process of pulling this data and thought that it would make a good post and allow me to try out writing some step by step instructions.
Here are the things that I was interested in.
- What creator has the most items where they are an author or co-author in the UNT Scholarly Works Repository?
- What is the most used item in the repository?
- What author has the highest “average item usage” ?
- How do these lists compare?
In order to answer these questions there are a number of steps that I had to go through in order to get the final data. This post will walk us through the steps later.
- Get a list of the item identifiers in the collection
- Grab the stats and metadata for each of the identifiers
- Convert metadata and stats into a format that can be processed
- Add up uses per item, per author, sort and profit.
So here we go.
Downloading the identifiers.
We have a number of API’s for each collection in our digital library. These are very very simple APIs compared to some of those offered by other systems, and in many cases our primary API consists of technologies like OAI-PMH, OpenSearch and simple text lists or JSON files. Here is the documentation for the APIs available for the UNT Scholarly Works Repository. For this project the API I’m interested in is the identifiers list. If you go to this URL http://digital.library.unt.edu/explore/collections/UNTSW/identifiers/ you can get all of the public identifiers for the collection.
Here is the WGET command that I use to grab this file and to save it as a file called untsw.arks
[vphill]$ wget http://digital.library.unt.edu/explore/collections/UNTSW/identifiers/ -O untsw.arks
Now that we have this file we can quickly get a count for the total number of items we will be working with by using the wc command.
[vphill]$ wc -l untsw.arks 3731 untsw.arks
We can quickly see that there are 3,731 identifiers in this file.
Next up we want to adjust that arks file a bit to get at just the name part of the ark, locally we call these either meta_ids or ids for short. I will use the sed command to get rid of the ark:/67531/ part of each line and then save the resulting line as a new file. Here is that command
sed "s/ark:/67531///" untsw.arks > untsw.ids
Now we have a file untsw.ids that looks like this:
metadc274983 metadc274993 metadc274992 metadc274991 metadc274998 metadc274984 metadc274980 metadc274999 metadc274985 metadc274995
We will use this file to now grab the metadata and usage stats for each item.
Downloading Stats and Metadata
For this step we will make use of an undocumented API for our system, internally it is called the “resource_object”. For a given item http://digital.library.unt.edu/ark:/67531/metadc274983/ if you append resource_object.json you will get the JSON representation of the resource object we use for all of our templating in the system. http://digital.library.unt.edu/ark:/67531/metadc274983/resource_object.json is the resulting URL. Depending on the size of the object, this resource object could be quite large because it has a bunch of data inside.
Two pieces of data that are important to us are the usage stats and the metadata for the item itself. We will make use of wget again to grab this info, and a quick loop to help automate the process a bit more. Before we grab all of these files we want to create a folder called “data” to store content in.
[vphill]$ mkdir data [vphill]$ for i in in `cat untsw.ids` ; do wget -nc "http://digital.library.unt.edu/ark:/67531/$i/resource_object.json" -O data/$i.json ; done
What this does, first we create a directory called data with the mkdir command.
Next we loop over all of the lines in the untsw.ids file by using the cat command to read the file. Each line or iteration of the loop, the variable $i will contain a new meta_id from the file.
Each iteration of the loop we will use wget to grab the resource_object.json and save it to a json file in the data directory named using the meta_id with .json appended to the end.
I’ve added the -nc option to wget that means “no clobber” so if you have to restart this step it won’t try and re-download items that have already been downloaded.
This step can take a few minutes depending on the size of the collection you are pulling. I think it took about 15 minutes for my 3,731 items in the UNT Scholarly Works Repository.
Converting the Data
For this next section I have three bits of code that I use to get at the data inside of the JSON files that we downloaded in “data” folder. I suggest now creating a “code” folder using the mkdir again so that we can place the following python scripts into them. The names for each of these files are as follows: get_creators.py, get_usage.py, and reducer.py.
#get_creators.py
import sys
import json
if len(sys.argv) != 2:
print "usage: %s <untl resource object json file>" % sys.argv[0]
exit(-1)
filename = sys.argv[1]
data = json.loads(open(filename).read())
total_usage = data["stats"]["total"]
meta_id = data["meta_id"]
metadata = data["desc_MD"].get("creator", [])
creators = []
for i in metadata:
creators.append(i["content"]["name"].replace("t", " "))
for creator in creators:
out = "t".join([meta_id, creator, str(total_usage)])
print out.encode('utf-8')
Copy the above text into a file inside your “code” folder called get_creators.py
#get_usage.py
import sys
import json
if len(sys.argv) != 2:
print "usage: %s <untl resource object json file>" % sys.argv[0]
exit(-1)
filename = sys.argv[1]
data = json.loads(open(filename).read())
total_usage = data["stats"]["total"]
meta_id = data["meta_id"]
title = data["desc_MD"]["title"][0]["content"].replace("t", " ")
out = "t".join([meta_id, str(total_usage), title])
print out.encode("utf-8")
Copy the above text into a file inside your “code” folder called get_usage.py
#!/usr/bin/env python
"""A more advanced Reducer, using Python iterators and generators."""
from itertools import groupby
from operator import itemgetter
import sys
def read_mapper_output(file, separator='t'):
for line in file:
yield line.rstrip().split(separator, 1)
def main(separator='t'):
# input comes from STDIN (standard input)
data = read_mapper_output(sys.stdin, separator=separator)
# groupby groups multiple word-count pairs by word,
# and creates an iterator that returns consecutive keys and their group:
# current_word - string containing a word (the key)
# group - iterator yielding all ["<current_word>", "<count>"] items
for current_word, group in groupby(data, itemgetter(0)):
try:
total_count = sum(int(count) for current_word, count in group)
print "%s%s%d" % (current_word, separator, total_count)
except ValueError:
# count was not a number, so silently discard this item
pass
if __name__ == "__main__":
main()
Copy the above text into a file inside your “code” folder called reducer.py
Now that we have these three scripts, I want to loop over all of the JSON files in the data directory and pull out information from them. First we use the get_usage.py script and redirect the output of that script to a file called usage.txt
[vphill]$ for i in data/*.json ; do python code/get_usage.py "$i" ; done > usage.txt
Here is what that file looks like when you look at the first ten lines.
metadc102275 447 Feeling Animal: Pet-Making and Mastery in the Slave's Friend metadc102276 48 An Extensible Approach to Interoperability Testing: The Use of Special Diagnostic Records in the Context of Z39.50 and Online Library Catalogs metadc102277 114 Using Assessment to Guide Strategic Planning metadc102278 323 This Side of the Border: The Mexican Revolution through the Lens of American Photographer Otis A. Aultman metadc102279 88 Examining MARC Records as Artifacts That Reflect Metadata Utilization Decisions metadc102280 155 Genetic Manipulation of a "Vacuolar" H+ -PPase: From Salt Tolerance to Yield Enhancement under Phosphorus-Deficient Soils metadc102281 82 Assessing Interoperability in the Networked Environment: Standards, Evaluation, and Testbeds in the Context of Z39.50 metadc102282 67 Is It Really That Bad? Verifying the extent of full-text linking problems metadc102283 133 The Hunting Behavior of Black-Shouldered Kites (Elanus Caeruleus Leucurus) in Central Chile metadc102284 199 Ecological theory and values in the determination of conservation goals: examples from temperate regions of Germany, United States of America, and Chile
It is a tab delimited file with three fields, the meta_id, the usage count and finally the title of the item.
The next thing we want to do is create another list of creators and their usage data. We do that in a similar was as in the previous step. The command below should get you where you want to go.
[vphill]$ for i in data/* ; do python code/get_creators.py "$i" ; done > creators.txt
Here is a sample of what this file looks like.
metadc102275 Keralis, Spencer D. C. 447 metadc102276 Moen, William E. 48 metadc102276 Hammer, Sebastian 48 metadc102276 Taylor, Mike 48 metadc102276 Thomale, Jason 48 metadc102276 Yoon, JungWon 48 metadc102277 Avery, Elizabeth Fuseler 114 metadc102278 Carlisle, Tara 323 metadc102279 Moen, William E. 88 metadc102280 Gaxiola, Roberto A. 155
Here again you have a tab delimited file with the meta_id, name and usage for that name in that item. You can see that there are five entries for the item metadc102276 because there were five creators for that item.
Looking at the Data
The final step (and the thing that we’ve been waiting for is to actually do some work with this data. This is easy to do with a few standard unix/linux command line tools. The work below will make use of the tools wc, sort, uniq, cut, and head
Most used items
The first thing that we can do with the usage.txt file is to see which items were used the most. If we use the following command you can get at this data.
[vphill]$ sort -t$'t' -k 2nr usage.txt | head
We need to sort the usage.txt file by the second column with the data being treated as numeric data. We would like this in reverse order or from the largest to the smallest. The sort command we use above uses the -t option to say that we want to treat the tab character as the delimiter instead of the default space character and the the -k option says to use the second column as a number in reverse order. We pipe this output to the head program which take the first ten results and spits them out. We should have something that looks like the following (formatted to a table for easier reading).
| meta_id | usage | title |
| metadc30374 | 5,153 | Appendices To: The UP/SP Merger: An Assessment of the Impacts on the State of Texas |
| metadc29400 | 5,075 | Remote Sensing and GIS for Nonpoint Source Pollution Analysis in the City of Dallas’ Eastern Watersheds |
| metadc33126 | 4,691 | Research Consent Form: Focus Groups and End User Interviews |
| metadc86949 | 3,712 | The First World War: American Ideals and Wilsonian Idealism in Foreign Policy |
| metadc33128 | 3,512 | Summary Report of the Needs Assessment |
| metadc86874 | 2,986 | Synthesis and Characterization of Nickel and Nickel Hydroxide Nanopowders |
| metadc86872 | 2,886 | Depression in college students: Perceived stress, loneliness, and self-esteem |
| metadc122179 | 2,766 | Cross-Cultural Training and Success Versus Failure of Expatriates |
| metadc36277 | 2,564 | What’s My Leadership Color? |
| metadc29807 | 2,489 | Bishnoi: An Eco-Theological “New Religious Movement” In The Indian Desert |
Creators with the most uses
The next thing we want to do is look at the creators that had the most collective uses in the entire dataset. For this we use the creators.txt file and grab only the name and usage field. We then sort by the name field so they are all in alphabetical order. We use the reducer.py script to add up the uses for each name (must be sorted before you do this step) and then we pipe that to the sort program again. Here is the command.
[vphill]$ cut -f 2,3 creators.txt | sort | python code/reducer.py | sort -t$'t' -k 2nr | head
Hopefully there are portions of the above command that are recognizable from the previous example (sorting by the second column and head) with some new things thrown in. Again I’ve converted the output to a table for easier viewing.
| Creator | Total Aggregated Uses per Creator |
| Murray, Kathleen R. | 24,600 |
| Mihalcea, Rada, 1974- | 23,960 |
| Cundari, Thomas R., 1964- | 20,903 |
| Phillips, Mark Edward | 20,023 |
| Acree, William E. (William Eugene) | 18,930 |
| Clower, Terry L. | 14,403 |
| Alemneh, Daniel Gelaw | 13,069 |
| Weinstein, Bernard L. | 13,008 |
| Moen, William E. | 12,615 |
| Marshall, James L., 1940- | 8,692 |
Publications Per Creator
Another thing that is helpful is to pull the list of publications per author which we can do easily with our creators.txt list.
Here is the command we will want to use.
[vphill]$ cut -f 2 creators.txt | sort | uniq -c | sort -nr | head
This command should be familiar from previous examples, the new command that I’ve added is uniq with the option to count the unique instances of each name. I then sort on that count in reverse order (highest to lowest) and take the top ten results.
The output will look something like this
267 Acree, William E. (William Eugene) 161 Phillips, Mark Edward 114 Alemneh, Daniel Gelaw 112 Cundari, Thomas R., 1964- 108 Mihalcea, Rada, 1974- 106 Grigolini, Paolo 90 Falsetta, Vincent 87 Moen, William E. 86 Dixon, R. A. 85 Spear, Shigeko
To keep up with the formatted tables, here are the top ten most prolific creators in the UNT Scholarly Works Repository.
| Creators | Items |
| Acree, William E. (William Eugene) | 267 |
| Phillips, Mark Edward | 161 |
| Alemneh, Daniel Gelaw | 114 |
| Cundari, Thomas R., 1964- | 112 |
| Mihalcea, Rada, 1974- | 108 |
| Grigolini, Paolo | 106 |
| Falsetta, Vincent | 90 |
| Moen, William E. | 87 |
| Dixon, R. A. | 86 |
| Spear, Shigeko | 85 |
Average Use Per Item
A bonus exercise you can do is combine the creators use counts with the number of items they have in the repository to identify their average item usage number. I did that to the top ten creators by overall use and you can see how that shows some interesting things too.
| Name | Total Aggregate Uses | Items | Use Per Item Ratio |
| Murray, Kathleen R. | 24,600 | 65 | 378 |
| Mihalcea, Rada, 1974- | 23,960 | 108 | 222 |
| Cundari, Thomas R., 1964- | 20,903 | 112 | 187 |
| Phillips, Mark Edward | 20,023 | 161 | 124 |
| Acree, William E. (William Eugene) | 18,930 | 267 | 71 |
| Clower, Terry L. | 14,403 | 54 | 267 |
| Alemneh, Daniel Gelaw | 13,069 | 114 | 115 |
| Weinstein, Bernard L. | 13,008 | 49 | 265 |
| Moen, William E. | 12,615 | 87 | 145 |
| Marshall, James L., 1940- | 8,692 | 71 | 122 |
It is interesting to see that Murray, Kathleen R. has both the highest aggregate uses as well as the highest Use Per Item Ratio. Other authors like Acree, William E. (William Eugene) who have many publications go down a bit in rank if you ordered by Use Per Item Ratio.
Conclusion
Depending on what side of the fence you sit on this post either demonstrates remarkable flexibility in the way you can get at data in a system, or it will make you want to tear your hair out because there isn’t a pre-built interface for these reports in the system. I’m of the camp that the way we’ve done things is a feature and not a bug but again many will have a different view.
How do you go about getting this data out of your systems? Is the process much easier, much harder or just about the same?
As always feel free to contact me via Twitter if you have questions or comments.